
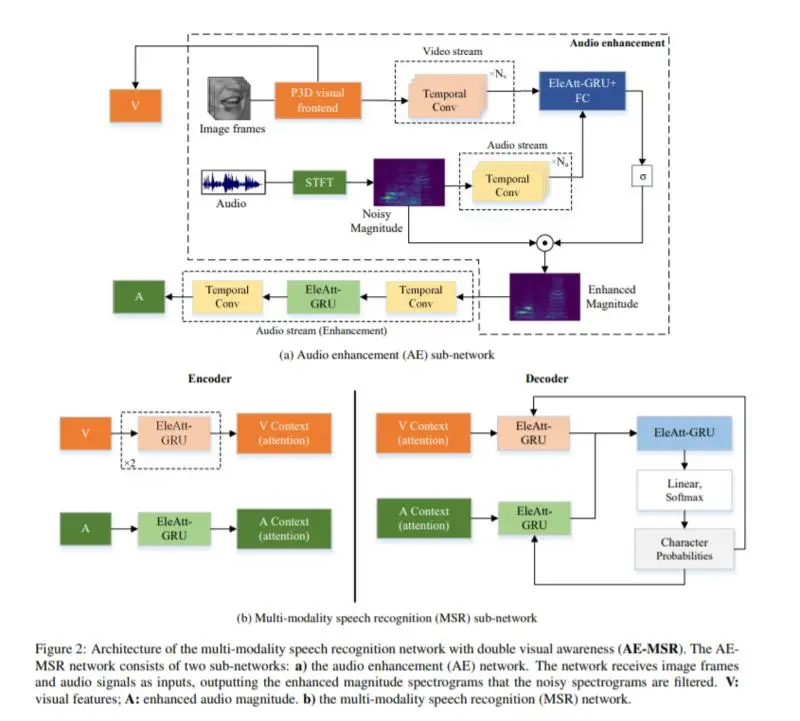
视觉通常被用作音频语音识别(ASR)的补充模态,尤其是在单独音频模态性能显著下降的嘈杂环境中。结合视觉模态,将ASR升级为多模态语音识别(multi-modality speech recognition, MSR)。本文提出了一个两阶段语音识别模型。在第一阶段,通过唇动的视觉信息将目标语音从背景噪声中分离出来,使模型能够清晰地理解。第二阶段,音频模态再次结合视觉模态,通过MSR子网络更好地理解语音,进一步提高识别率。还有一些其他的关键贡献:我们介绍了伪三维剩余卷积(P3D)为基础的视觉前端提取更多的判别性特征; 我们用时域卷积网络(TCN)将时域卷积块从1D ResNet升级到更适合于时域任务的时域卷积网络(TCN); MSR子网络建立在元素智能选通递归单元(eleat - gru)的顶部,在长序列中比Transformer更有效。我们在LRS3-TED和LRW数据集上进行了大量的实验。我们的两阶段模型(音频增强多模态语音识别,AE-MSR)始终以显著的优势实现了最先进的性能,这证明了AE-MSR的必要性和有效性。
成为VIP会员查看完整内容
相关内容

CVPR is the premier annual computer vision event comprising the main conference and several co-located workshops and short courses. With its high quality and low cost, it provides an exceptional value for students, academics and industry researchers.
CVPR 2020 will take place at The Washington State Convention Center in Seattle, WA, from June 16 to June 20, 2020.
http://cvpr2020.thecvf.com/
专知会员服务
69+阅读 · 2020年6月19日
专知会员服务
26+阅读 · 2019年11月23日
Arxiv
6+阅读 · 2018年4月9日
Arxiv
7+阅读 · 2018年1月28日
相关VIP内容
专知会员服务
69+阅读 · 2020年6月19日
专知会员服务
26+阅读 · 2019年11月23日
相关资讯