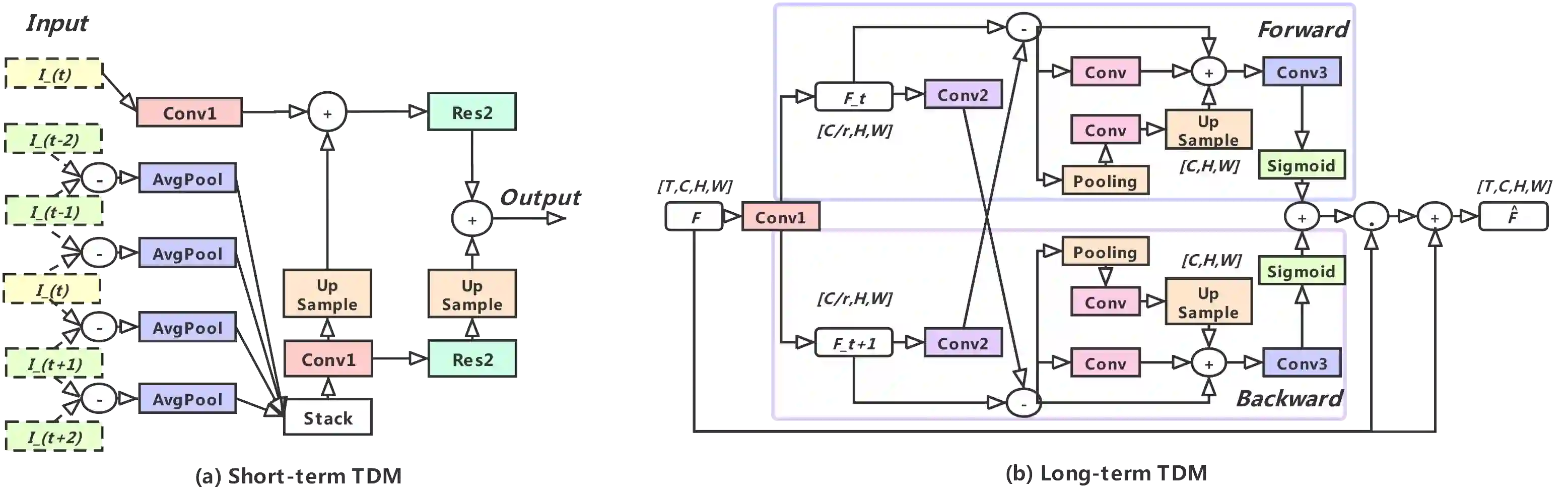
Temporal modeling still remains challenging for action recognition in videos. To mitigate this issue, this paper presents a new video architecture, termed as Temporal Difference Network (TDN), with a focus on capturing multi-scale temporal information for efficient action recognition. The core of our TDN is to devise an efficient temporal module (TDM) by explicitly leveraging a temporal difference operator, and systematically assess its effect on short-term and long-term motion modeling. To fully capture temporal information over the entire video, our TDN is established with a two-level difference modeling paradigm. Specifically, for local motion modeling, temporal difference over consecutive frames is used to supply 2D CNNs with finer motion pattern, while for global motion modeling, temporal difference across segments is incorporated to capture long-range structure for motion feature excitation. TDN provides a simple and principled temporal modeling framework and could be instantiated with the existing CNNs at a small extra computational cost. Our TDN presents a new state of the art on the Something-Something V1 and V2 datasets and is on par with the best performance on the Kinetics-400 dataset. In addition, we conduct in-depth ablation studies and plot the visualization results of our TDN, hopefully providing insightful analysis on temporal difference operation. We release the code at https://github.com/MCG-NJU/TDN.
翻译:为缓解这一问题,本文展示了一个新的视频结构,称为“时空差异网络”,重点是捕捉多尺度的时间信息,以有效行动识别。我们的时空模型的核心是设计一个高效的时间模块(TDM),明确利用时间差异操作者,并系统地评估其对短期和长期运动模型的影响。为了充分捕捉整个视频的时间信息,我们的TDN以两个层面的差异模型模式建立起来。具体地说,对于本地运动模型而言,使用连续框架的时间差异来提供2DCNN的细微动作模式,而对于全球运动模型而言,则将各部分之间的时间差异纳入其中,以捕捉运动特征感召的远程结构。TDN提供了一个简单而有原则的时间模型框架,并且可以与现有的CNN一起以少量额外的计算成本进行即时化。我们的TDN提供了一种关于SomeMV1和V2数据集的新状态,并且与Kinitical-N运动的优性动作模型模型模型模型模式相匹配,而对于Kinitical-N-N运动的模型模型模型模型模型模型模型模型则结合了。我们进行了有希望的模型化研究,我们用的是,我们对 TD/Simalimalalalalismexal 的分析,我们用了我们进行了一种模型分析。