简评 | Video Action Recognition 的近期进展
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者 | 孟让
来源 | https://zhuanlan.zhihu.com/p/59915784
已获作者授权,请勿二次转载
一. 视频分类主流方法
2-stream,结合光流和RGB,RGB支路可以是2D CNN 也可以是I3D
3D CNN,卷积核多出时序上的维度,spatial-temporal 建模,变形是时空分离的伪3d、(2+1)D等
时序信息用RNN建模
传统方法,先进行密集跟踪点采样(角点提取/背景去除),对密集采样点进行光流计算获取一定帧长的轨迹,沿着轨迹进行一些如SIFT/HOG的特征提取,NIPS2018有一篇轨迹卷积将以上过程NN化。
介绍以下几篇文章的思路。
1. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
2. A Closer Look at Spatiotemporal Convolutions for Action Recognition
3. Collaborative Spatiotemporal Feature Learning for Video Action Recognition
4. SlowFast Networks for Video Recognition
5. Videos as Space-Time Region Graphs
6. Temporal Shift Module for Efficient Video Understanding
7. Interaction-aware Spatio-temporal Pyramid Attention Networks for Action Classification
8. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
9. Attention Clusters: Purely Attention Based Local Feature Integration for Video Classification
二. 近期进展
ECCV2016 | Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
这篇文章的video处理方法是以后文章的范式,是基础的video输入pipeline。网络结构是2-stream的,主要针对长程时间context获取和video的过拟合问题。
首先针对时间长程context,文章基于帧间冗余的存在,在数据上作稀疏帧采样方法,扩大感受野,去除帧间冗余。具体做法就是将video分作K个segment,每个segment中随机去取一个snippet,分别得到每个snippet的logits,然后对K个logits中属于同类的得分取平均,以代表整个video的类别最后的logits。rgb和flow的2-stream网络的得分融合就不再赘述了。
损失函数是交叉熵:
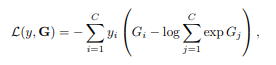
G则是snippets-logits的平均值。
另文章许多train/test tricks,可以作为video的常规操作。
CVPR2018 | A Closer Look at Spatiotemporal Convolutions for Action Recognition
本文中比较了存2D卷积、2D+3D混合卷积还有spatio-tempoal 分离的2+1D卷积和的效果。方法很简单。提到的2d+3d混合卷积的做法是浅层用3d,深层用2d,理由是motion建模是一种low/mid level。光流计算是传统主流的一种motion建模,即按某种假设找到相邻帧的对应像素点的位移,无外乎平移和旋转。
具体细节之前写过一篇:CVPR2018 | R(2+1)D结构:视频动作识别中的时空卷积深度探究(https://zhuanlan.zhihu.com/p/48267318)
CVPR2019 | Collaborative Spatiotemporal Feature Learning for Video Action Recognition
主要是将InceptionV3的分解卷积核的思想拓展到时-空领域,并结合self-attention机制。而且分解的卷积核参数共享(转置一下继续使用)。不同view featuremaps 施加self-attention机制(加可学习权重求和)。实现spatiotemporal collaboration。如下图:
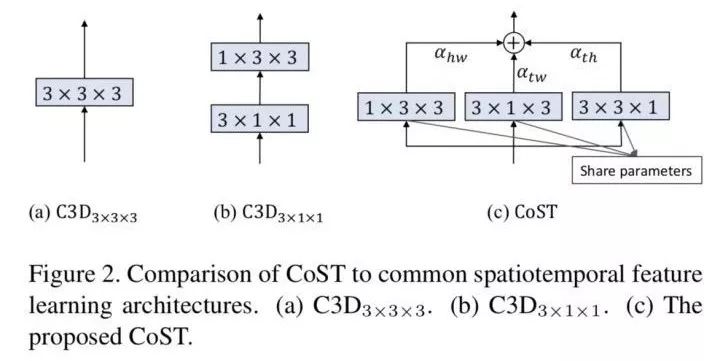
对一个video cube的hw,tw, th分别作2D卷积,然后加权sum融合起来。三个view的2D卷积核,是共享的,即一个核的转置。
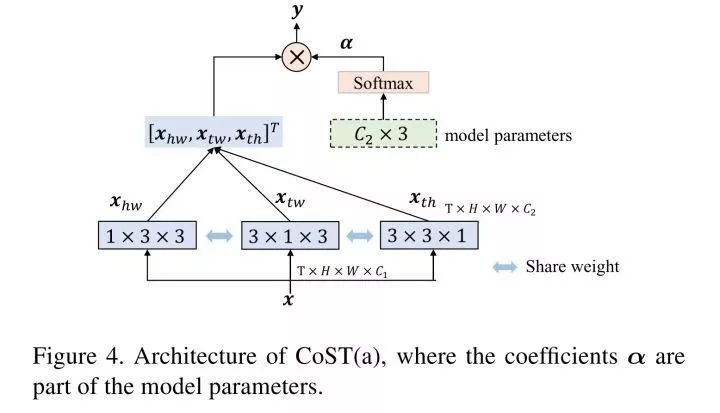
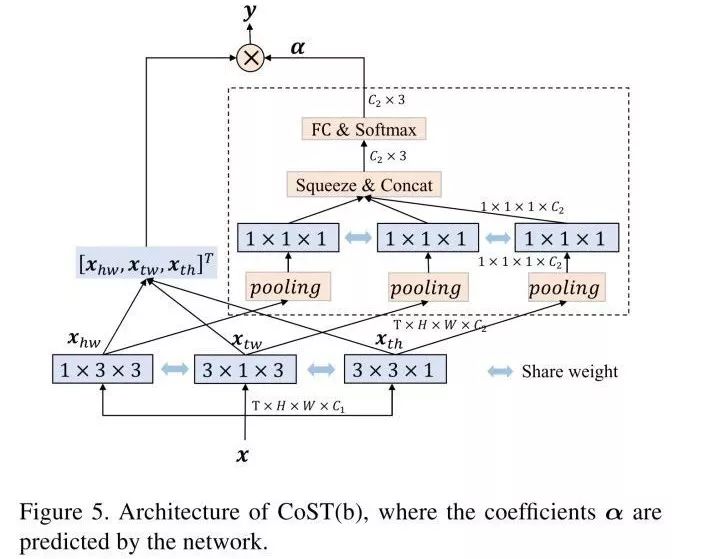
加权系数是可学习的C2 * 3的向量,C2是输出通道数。文章对比了两种加权系数学习方法,一种是作为model params接softmax,bp调节;一种是从featuremaps得来的,self-attention机制。ablation实验表明。self-attention的加权系数方法效果较好。两种框架如图:
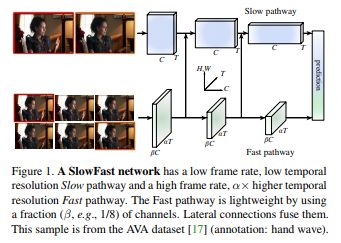
2018.12 | SlowFast Networks for Video Recognition
文章时空交互的方法是
1)两路3d卷积,分别侧重时间fast和空间slow
2)将侧重空间的支路信息融合入时间支路
两个支路slow和fast指的是T维的卷积核大小核跨步不同。fast路的时间维度卷积核大小为aT,时间维度stride为s/a,通道数为c/a,比较轻量;
Slow支路时间维度卷积核大小为T,时间维度stride为s,通道数为c。a=8.配置如下:
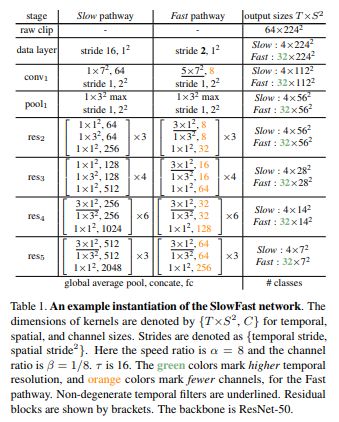
网络结构就是以上两种3d卷积的支路,中间将slow1支路fuse到fast,有三种fusion方法
1) time2channel:reshapefast维度的[bC, aT, S, S] to [abC, T, S, S]
2) 对fast路featuremaps进行temporal stride sample 统一时间维度
3)fast接跨步3d卷积统一时间维度
不同的效果:
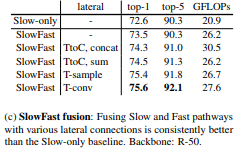
2018.12 | Videos as Space-Time Region Graphs
文章先用MSCOCO预训练的RPN(ResNet-50 with FPN)对每一帧进行目标检测,提取video感兴趣区域(bbox).

bbox目前是和类别和运动都无关的,然后对bbox作RoIAlign+Maxpooling获得一个1 * 1* d的特征向量,作为之后推理的Graph的node。文章建立了两个图,一个推理整个video中所有RoI间相关关系,一个推理相邻时序的RoI间的时空关系。backbone是i3D,图卷积推理和featuremaps的gloabal average poiling之后的向量concat一起后接FC进行分类。以下是整体网络结构:
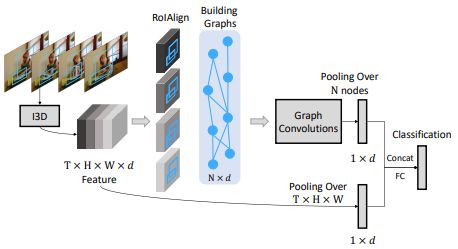
Similarity Graph
一段视频提取N个bbox(文章每帧提取50个bbox,不同数据集不同,但影响不是很大),得到图卷积输入X(N * d),然后先学习的方式得到邻接矩阵。对于每个节点接FC获得d * 1的输出向量,然后每个向量之间gram,得到所有节点两两之间的邻接情况置信度。所有置信度softmax正则化之后组成一个邻接矩阵。最后文章希望不同时序的同一个目标或者有动作作用的目标节点之间具有高置信度。
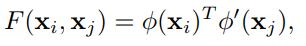
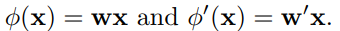
Spatial-Temporal Graph
以上建立的邻接矩阵没有考虑到时序和空间位置关系,所以文章根据相邻两帧之间bbox重叠程度越大,邻接矩阵对应元素越大。分别帧之间的前后/后前顺序分别建立两个图。
以上两种三个图,分成两个分支分别图卷积,最后一层sum融合。文章的训练上是backbone和GCN分别训练好之后再一起end2end fine tune。
关于两种图之间的ablation实验也表明,忽略时序的similarity graph确实比s-t graph效果好一些,这一点呼应了AttentionCluster中未考虑时序依然可以得出较好效果。但是两者结合起来利用时序信息的效果更好。
文章也分析了加入GCN之后对于连续型动作、大姿态动作、人物交互动作有较好鲁棒性。
2018.11 | Temporal Shift Module for Efficient Video Understanding
文章主要思路就是在2Dspatio卷积的时候,每一个通道上有一个时序的平移,这样一次2d卷积就可以感受到其他时间上的空间信息。
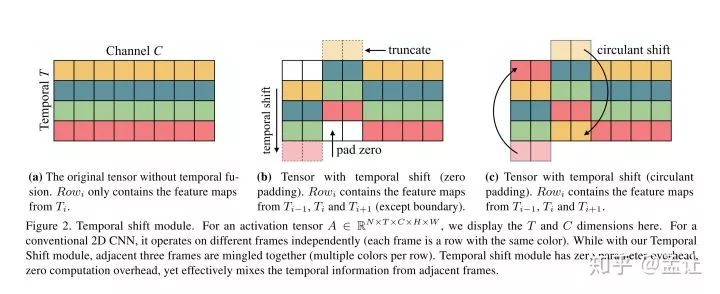
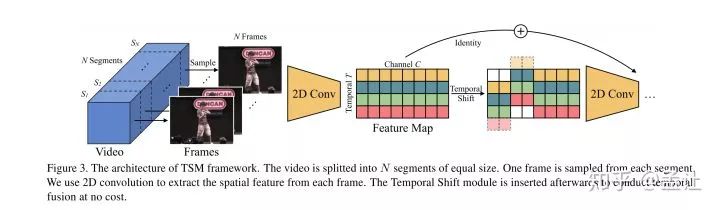
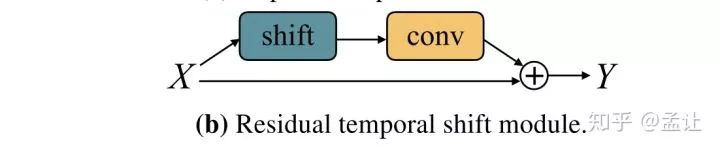
这是一种不加计算量加入时间维度的方法。对于shift之后的pad方法,就是pad zero。将shift出去的补到后面实验证明效果不好,文章认为主要是因为破坏了时序。
但是文章只是从shift通道占总通道比例上进行Ablation实验分析,比较1/2、1/4、1/8,其中1/4效果最好。
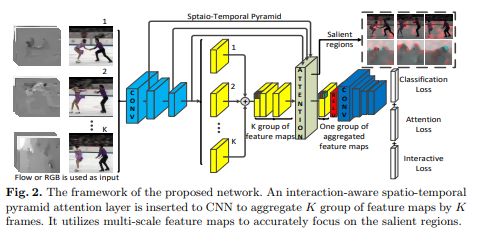
ECCV2018 | Interaction-aware Spatio-temporal Pyramid Attention Networks for Action Classification
本文的方法主要在小数据集如UCF101,HMD51, untrimmed Charades上做了实验。文章仿照PCA过程提取主成分以形成Attention。backbone为2-stream结构。
文章思路主要过程是对pyramid的feature maps进行PCA,变换矩阵NN化。首先将(C, H, W)的特征图X展成(C, HW),然后对其前N阶段特征图下采样(Max pooling)到最后一层同样的尺寸同样展平。对于这些展平的特征图,接fc。不同层的输出进行融合(点乘)+l2-norm,接softmax得到一个attention map A,和原来的X相乘,M=AX,reshape之后得到(C, H, W)的判别性特征。
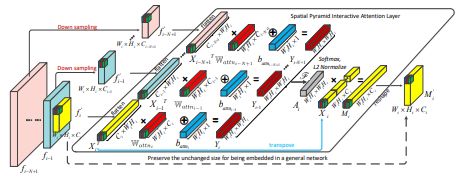
对于 video而言,文章采用的是2-stream结构,所以RGB路只是TSN的输入范式,每帧分别2d cnn提取特征,得到(C, K, H, W)的特征,展平为(C, KHW)。W,b矩阵依然为(HW, C)大小,最后得到的M尺寸(C, H, W)实现了时序融合。
PCA的目标是从远数据空间中找到方差最大且相互正交的坐标标轴来降维度,同时提取主要成分。方差大代表了差异性强,特征显著而具代表性。所以对数据的协方差矩阵进行SVD或者特征值分解,去除最大的K个特征值对应的特征向量组成变换矩阵。相应的变换矩阵S满足:
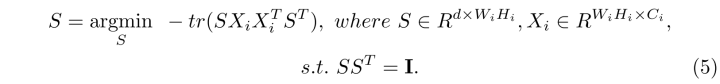
使得S是一个正交矩阵。
所以文章的interactive loss的形式模仿特征值分解PCA:
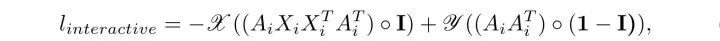
对此loss优化使得M的特征值之和(迹)最大,且A为正交阵。
另,文章使用的attention loss ,是为了让不同尺度产生的attention尽可能表示不同parts,使得互相之间差异尽可能大:
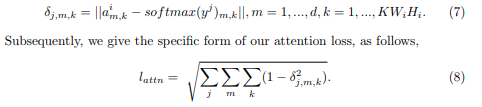
整体的损失函数:
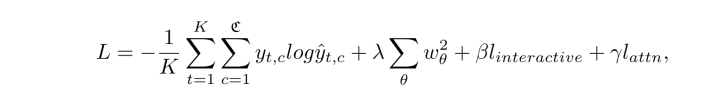
整体框架:
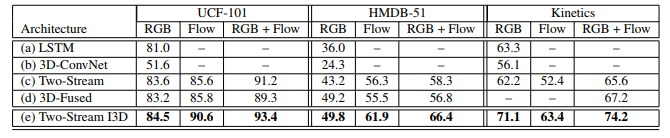
2018.2 | Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
将2D模型中的核参数在时间维上复制N次,形成3D核的参数,同时除以N,保证尺度输出和2D上一样;别的非线性层还有pool和2D模型一样。可以利用imagenet pre-train模型。
文章还讨论时空感受野相对增长速度的问题。认为若相对spatial而言temporal感受野如果增高过快,会破坏早期的特征检测,混淆不同物体的边缘;时间感受野增长过慢则不利于对动态的把握。
文章解释了一下光流计算相对于3d卷积的优势在于recurrent。这里我复盘了一下光流计算,感觉加入光流涨点应该是因为motion先验知识的加入。
2017.11 | Attention Clusters: Purely Attention Based Local Feature Integration for Video Classification
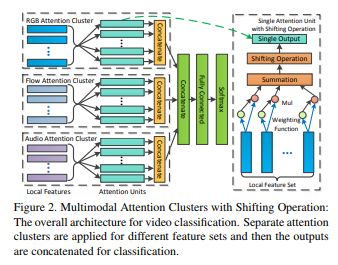
这篇文章的思路是很容易想到的,将attention机制用在时-空上,并引导attention。文章认为连续帧间冗余本来就很大,所以局部特征是很接近的;时间上long-term context不是必要的,而且动作的时间顺序可不是必要的。只需要找出一个动作最关键的帧就可以。获得了2017年activenet冠军。或许从分类角度出发,那些认为不必要的信息可能是不影响结果的。另,文章结合了audio,用audio结构vision。加上光流,共三个模态信息。以其中RGB为例介绍一下思路如下。首先局部特征提取,用Imagenet_pre-trained 的 2D Inception-ResNet-v2 fineturn 训练集。数据输入pipeline使用TSN,得到每一帧local feature。一个video表示成为一个local feature set。基于作者认为的时间 ‘apporaximately' 无序,使用随机从一个set采样的方法来数据增广。然后是attention实现,对于一个video,得到一个local feature set X:
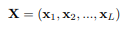
X是一个L * M的矩阵,L是帧数。attention方法则是SENet类似的temporal-wise attention,不过文章实验发现一个FC层效果好于两个。多个这种SE模块获得video不同的‘parts’,为了使得不同attention关注不同的frame,加入一个线性变换和L2(和IN类似,不过I是不同temporal支路,'TN'吧),然后concat一起分类。结构如下图:
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个好看啦~





