文献综述
·

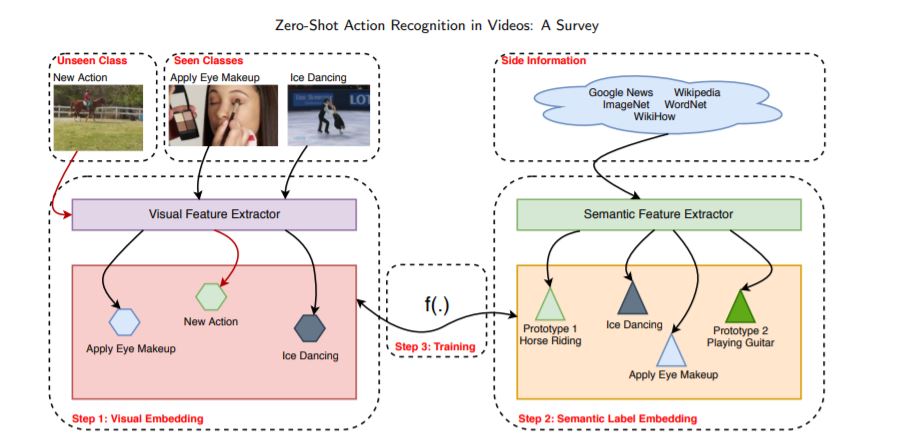
零样本动作识别是近年来备受关注的研究领域,针对图像和视频中物体、事件和动作的识别提出了多种方法。由于收集、注释和标记视频是一项困难而费力的任务,因此需要一些方法来将实例从模型训练中不存在的类中分类,特别是在复杂的自动视频理解任务中。我们发现在文献中有许多可用的方法,然而,很难对哪些技术可以被认为是最先进的技术进行分类。尽管有一些关于静止图像零样本动作识别的调研和实验,但是没有针对视频的研究。因此,在这篇文章中,我们提出了一个调查的方法,包括技术进行视觉特征提取和语义特征提取,以及学习这些特征之间的映射,特别是零镜头动作识别的视频。我们还提供了一个完整的数据集,实验和协议的描述,提出了开放的问题和未来的工作方向,这对计算机视觉研究领域的发展至关重要。
成为VIP会员查看完整内容
相关内容
专知会员服务
100+阅读 · 2019年11月23日
相关主题
相关VIP内容
专知会员服务
100+阅读 · 2019年11月23日
相关资讯
相关论文