【推荐】视频目标分割基础
转自:爱可可-爱生活
This is the first in a two part series about the state of the art in algorithms for Video Object Segmentation. The first part will be an introduction to the problem and it’s “classic” solutions. We will briefly cover:
The problem, the datasets, the challenge
A new dataset that we’re announcing today!
The two main approaches from 2016: MaskTrack and OSVOS. These are the algorithms upon which all other works are based.
In the second part, which is more advanced, I will present a comparison table of all the published approaches to the DAVIS-2017 Video Object Segmentation challenge, summarize and highlight selected works and point to some emerging trends and directions.
The posts assume familiarity with some concepts in computer vision and deep learning, but are quite accessible. I hope to make a good introduction to this computer vision challenge and bring newcomers quickly up to speed.
Introduction
There are three classic tasks related to objects in computer vision: classification, detection and segmentation. While classification aims to answer the “what?”, the goal of the latter two is to also answer the “where?”, and segmentation specifically aims to do it at the pixel level.
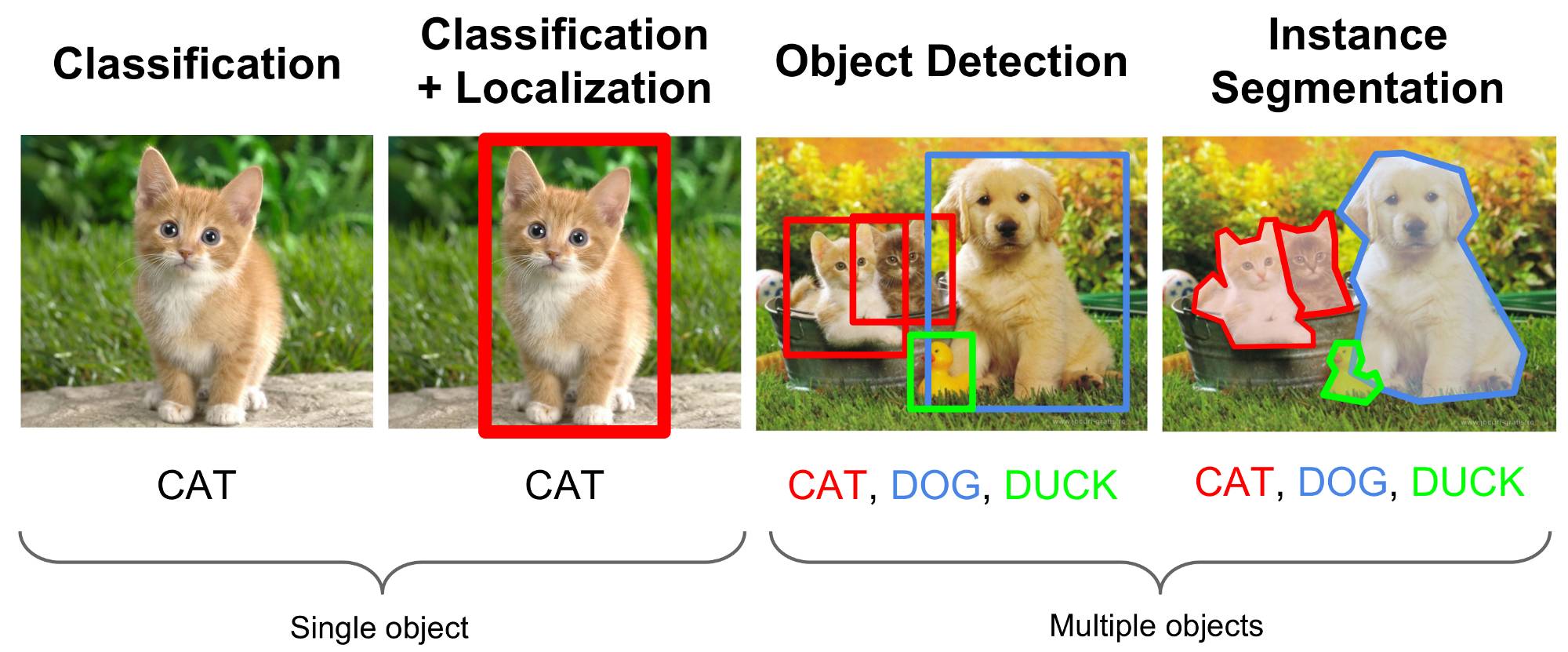
In 2016 we have seen semantic segmentation mature and perhaps even begin to saturate existing datasets. Meanwhile, 2017 has been somewhat of a breakout year for video related tasks: action classification, action (temporal) segmentation, semantic segmentation, etc. In these posts we will focus on Video Object Segmentation.
The problem, the datasets, the challenge
Assuming reader familiarity with semantic segmentation, the task of video object segmentation basically introduces two differences:
We are segmenting general, NON-semantic objects.
A temporal component has been added: our task is to find the pixels corresponding to the object(s) of interest in each consecutive frame of a video.
链接(需翻墙):
https://medium.com/@eddiesmo/video-object-segmentation-the-basics-758e77321914
原文链接:
https://m.weibo.cn/1402400261/4153615126478249



