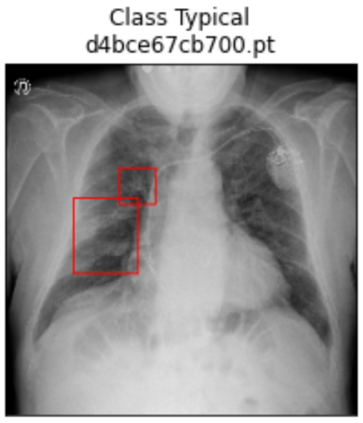
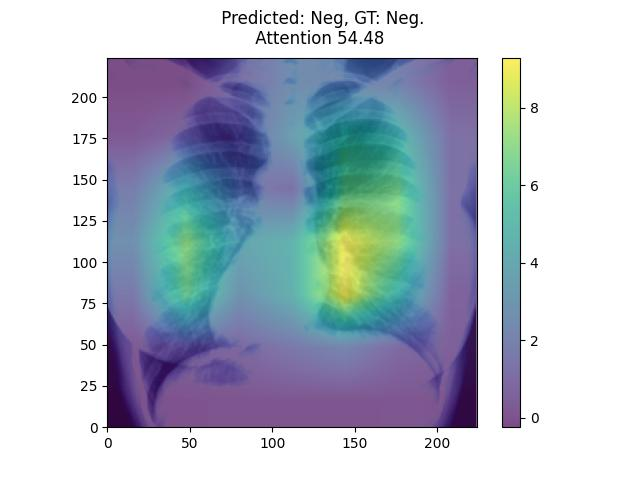
Deep learning technologies have already demonstrated a high potential to build diagnosis support systems from medical imaging data, such as Chest X-Ray images. However, the shortage of labeled data in the medical field represents one key obstacle to narrow down the performance gap with respect to applications in other image domains. In this work, we investigate the benefits of a curricular Self-Supervised Learning (SSL) pretraining scheme with respect to fully-supervised training regimes for pneumonia recognition on Chest X-Ray images of Covid-19 patients. We show that curricular SSL pretraining, which leverages unlabeled data, outperforms models trained from scratch, or pretrained on ImageNet, indicating the potential of performance gains by SSL pretraining on massive unlabeled datasets. Finally, we demonstrate that top-performing SSLpretrained models show a higher degree of attention in the lung regions, embodying models that may be more robust to possible external confounding factors in the training datasets, identified by previous works.
翻译:深层学习技术已经证明,从医疗成像数据(如Chest X-Ray图像)建立诊断支持系统的潜力很大,然而,医疗领域标签数据短缺是缩小其他图像应用领域性能差距的主要障碍之一。在这项工作中,我们调查了在Covid-19病人的胸X-Ray图像中完全监督的肺炎识别培训制度(SSL)课程自我监督学习(SSL)预培训计划的好处。我们显示,SLS课程预培训利用了无标签数据,超模了从刮伤中培训的模型,或预先在图像网络上培训,表明SSL在大规模无标签数据集上培训业绩收益的潜力。最后,我们证明,最优秀的SSL培训模式在肺部区域表现出了更高程度的注意力,体现了可能更强有力的模型,以适应培训数据集中可能存在的外部混杂因素,这些模型是以前的作品所查明的。