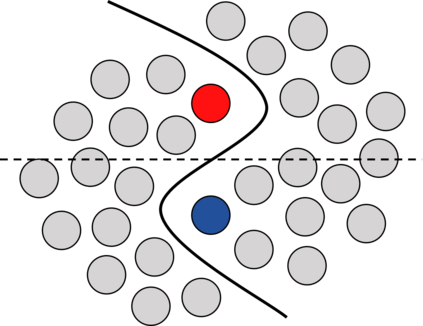
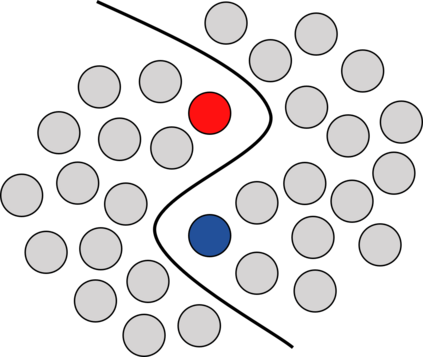
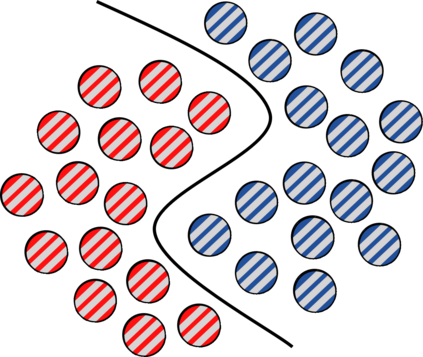
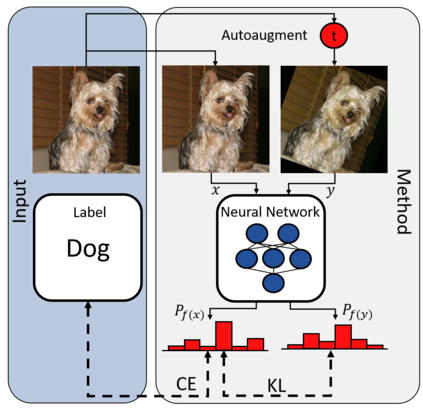
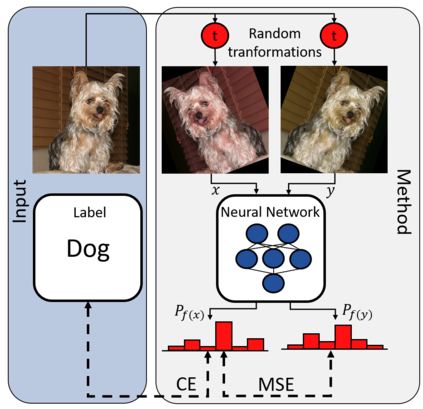
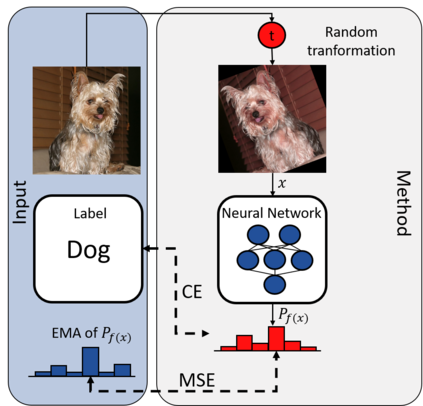
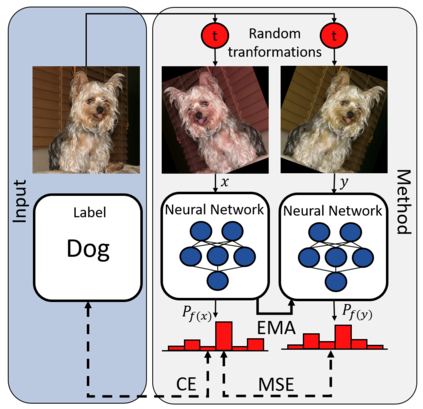
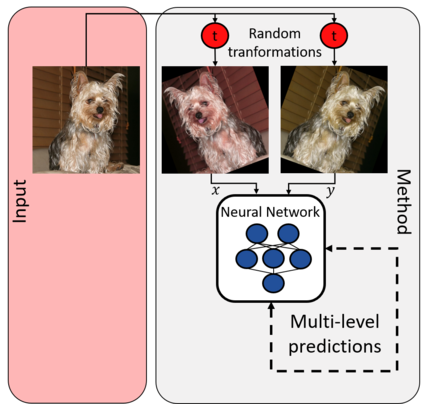
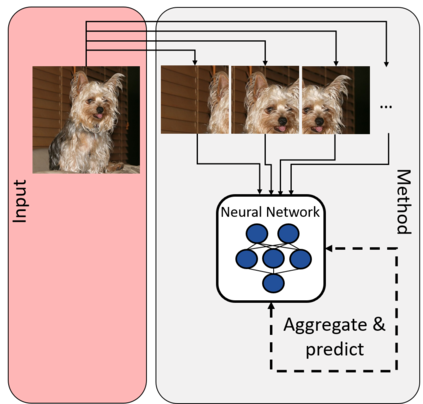
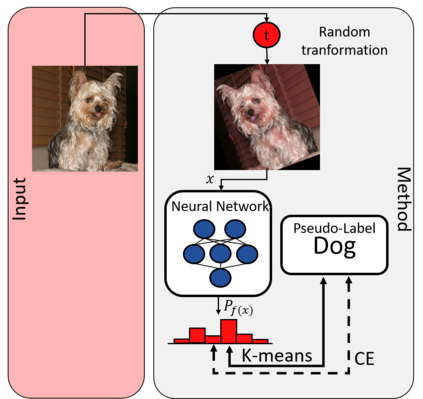
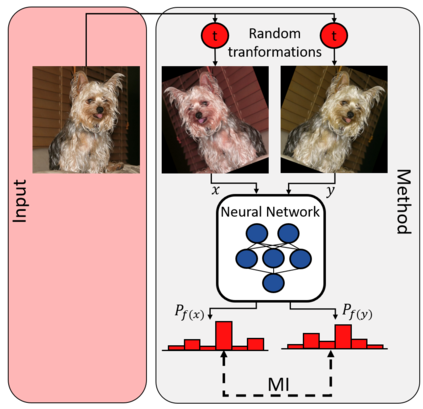
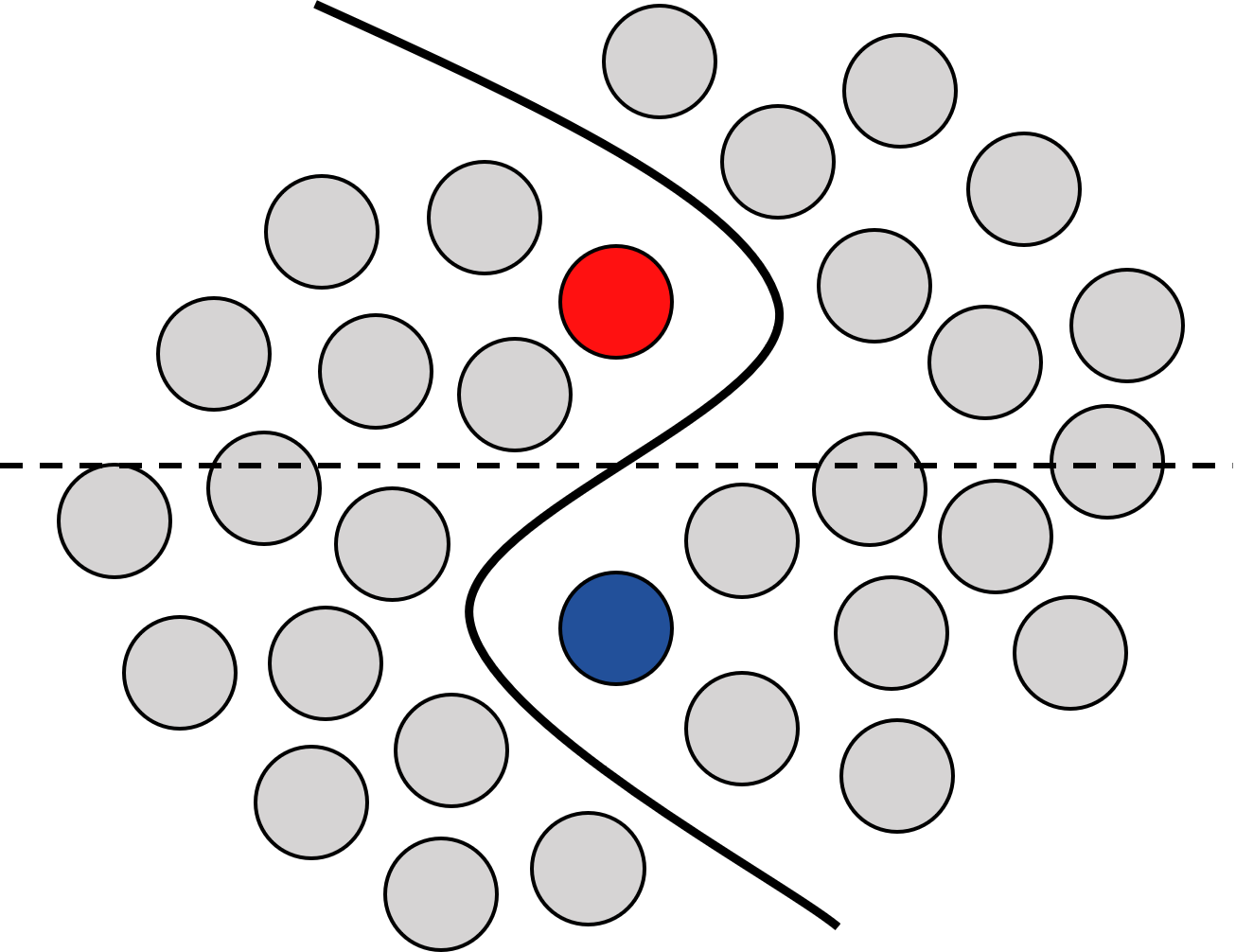
While deep learning strategies achieve outstanding results in computer vision tasks, one issue remains. The current strategies rely heavily on a huge amount of labeled data. In many real-world problems it is not feasible to create such an amount of labeled training data. Therefore, researchers try to incorporate unlabeled data into the training process to reach equal results with fewer labels. Due to a lot of concurrent research, it is difficult to keep track of recent developments. In this survey we provide an overview of often used techniques and methods in image classification with fewer labels. We compare 21 methods. In our analysis we identify three major trends. 1. State-of-the-art methods are scaleable to real world applications based on their accuracy. 2. The degree of supervision which is needed to achieve comparable results to the usage of all labels is decreasing. 3. All methods share common techniques while only few methods combine these techniques to achieve better performance. Based on all of these three trends we discover future research opportunities.
翻译:虽然深层次的学习战略在计算机愿景任务方面取得了杰出的成果,但有一个问题仍然存在。目前的战略严重依赖大量贴标签的数据。在许多现实世界中,创建如此多的贴标签的培训数据是不可行的。因此,研究人员试图将未贴标签的数据纳入培训过程,以便以较少的标签实现同等结果。由于大量同时进行的研究,很难跟踪最近的发展动态。在本次调查中,我们提供了在图像分类中经常使用的技术和方法的概览,而标签较少。我们比较了21种方法。我们在分析中发现了三大趋势。1. 最新技术基于其准确性,可以推广到真实世界的应用。 2. 实现与所有标签使用相类似的结果所需的监督程度正在下降。3. 所有方法都共享共同技术,但只有很少方法结合这些技术来取得更好的业绩。我们发现未来研究机会的所有这三个趋势。