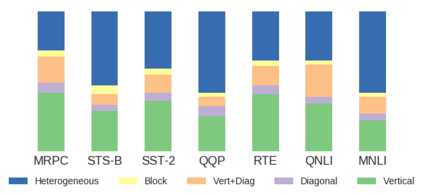
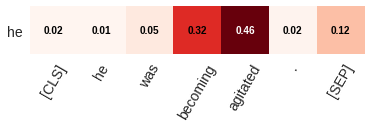
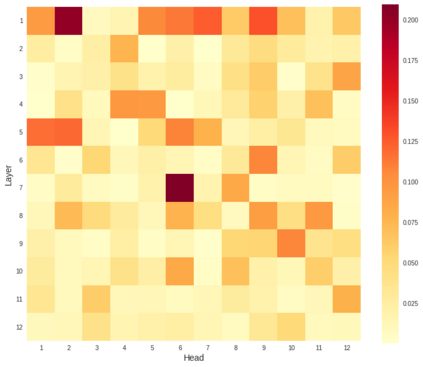
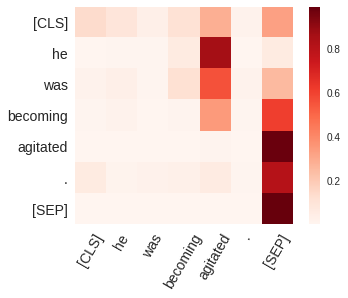
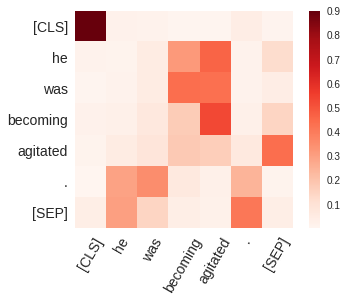
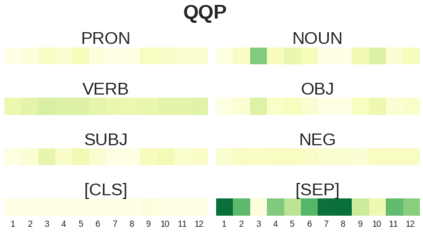
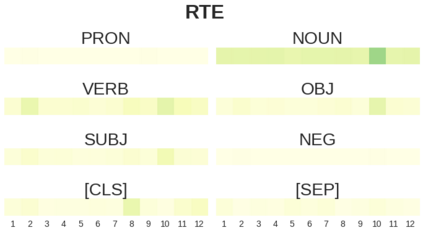
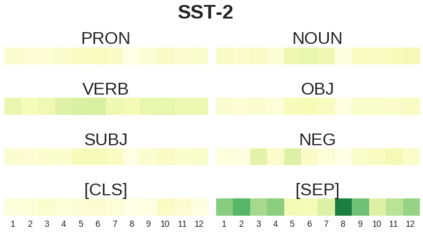
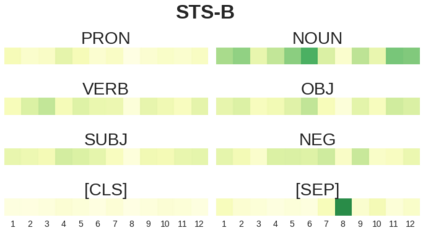
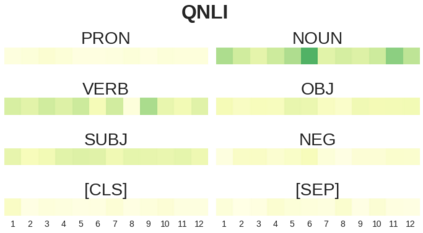
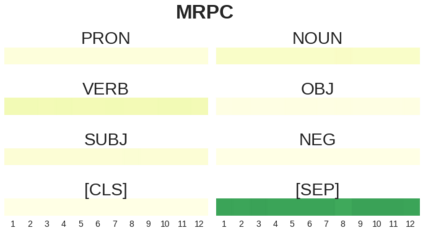
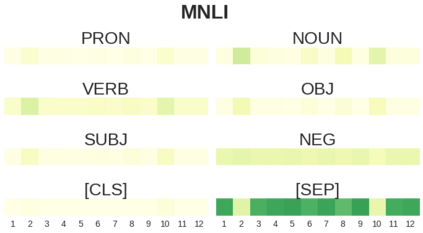
BERT-based architectures currently give state-of-the-art performance on many NLP tasks, but little is known about the exact mechanisms that contribute to its success. In the current work, we focus on the interpretation of self-attention, which is one of the fundamental underlying components of BERT. Using a subset of GLUE tasks and a set of handcrafted features-of-interest, we propose the methodology and carry out a qualitative and quantitative analysis of the information encoded by the individual BERT's heads. Our findings suggest that there is a limited set of attention patterns that are repeated across different heads, indicating the overall model overparametrization. While different heads consistently use the same attention patterns, they have varying impact on performance across different tasks. We show that manually disabling attention in certain heads leads to a performance improvement over the regular fine-tuned BERT models.
翻译:目前,基于BERT的架构为许多NLP任务提供了最先进的业绩,但对于有助于其成功的确切机制却知之甚少。在目前的工作中,我们侧重于自我关注的解释,这是BERT的一个基本基本组成部分之一。我们利用GLUE任务的一个子集和一套手工制作的特质,提出方法,对BERT个人头目的个人编码的信息进行定性和定量分析。我们的调查结果表明,不同头目之间重复的注意模式有限,表明总体模式过于平衡。虽然不同的头目始终使用同样的注意模式,但对不同任务的业绩有着不同的影响。我们表明,某些头目手工分散的注意力,导致对定期微调的BERT模型的业绩改进。