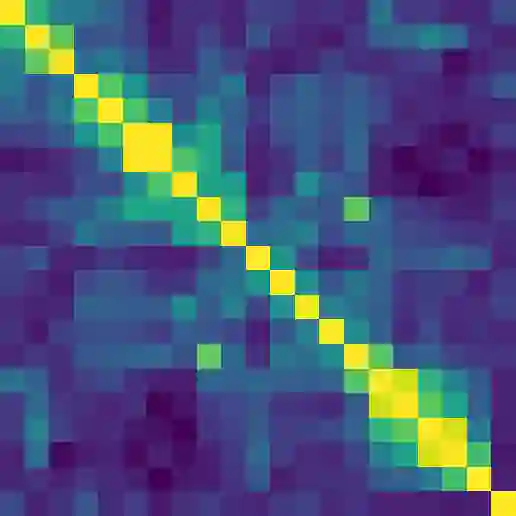
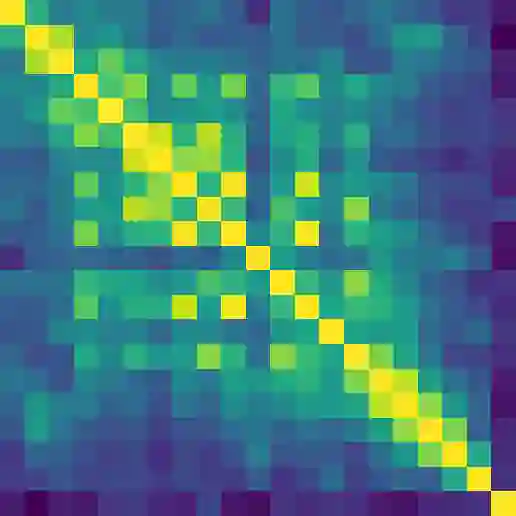
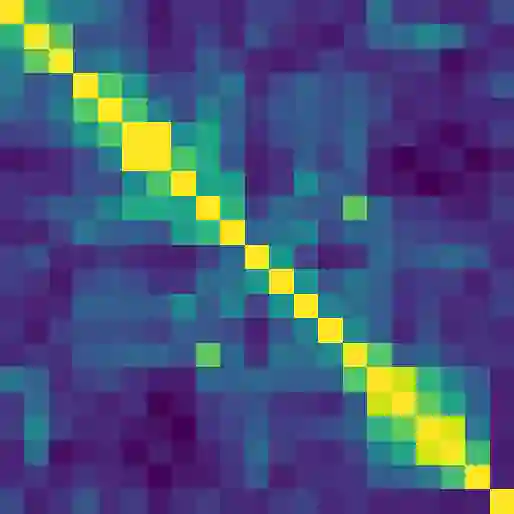
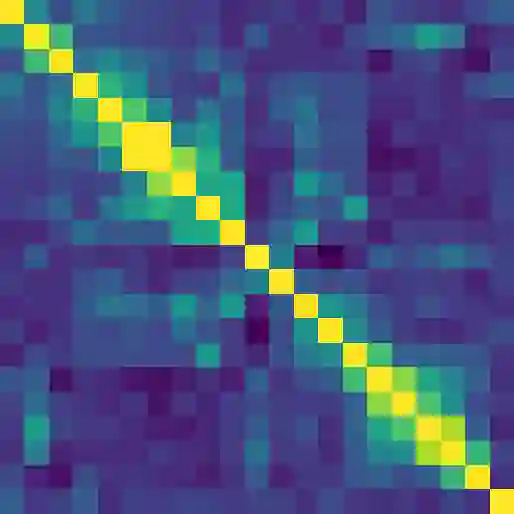
Contextual word representations derived from pre-trained bidirectional language models (biLMs) have recently been shown to provide significant improvements to the state of the art for a wide range of NLP tasks. However, many questions remain as to how and why these models are so effective. In this paper, we present a detailed empirical study of how the choice of neural architecture (e.g. LSTM, CNN, or self attention) influences both end task accuracy and qualitative properties of the representations that are learned. We show there is a tradeoff between speed and accuracy, but all architectures learn high quality contextual representations that outperform word embeddings for four challenging NLP tasks. Additionally, all architectures learn representations that vary with network depth, from exclusively morphological based at the word embedding layer through local syntax based in the lower contextual layers to longer range semantics such coreference at the upper layers. Together, these results suggest that unsupervised biLMs, independent of architecture, are learning much more about the structure of language than previously appreciated.
翻译:从经过训练的双向双向语言模型(BILMs)中得出的上下文文字表达方式最近显示,这些表达方式大大改进了国家语言平台的广泛任务,然而,关于这些模型如何和为什么如此有效,仍有许多问题。在本文件中,我们提交了一份详细的实证研究,说明神经结构的选择(如LSTM、CNN或自我关注)如何影响最终任务准确性和所学到的演示形式的质量特性。我们显示,速度和准确性之间存在着平衡,但所有架构都学习了优于四种具有挑战性的国家语言平台任务所用语言的高质量背景表达方式。此外,所有架构学习了与网络深度不同,从完全基于词嵌入层的形态学表现方式到基于较低背景层的本地语法,到上层这种相近的更远范围语义学。这些结果表明,独立于结构的未受控制的双级语言模型更多地了解语言结构。