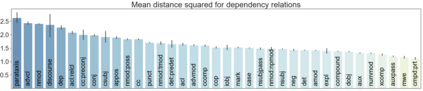
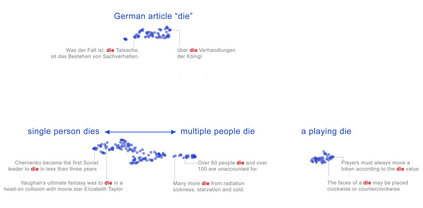
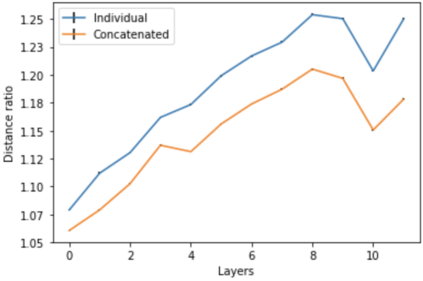
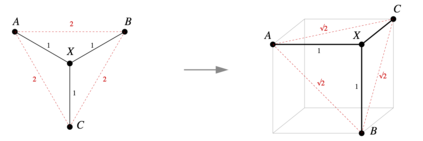
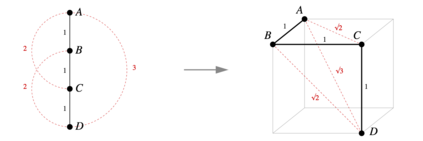
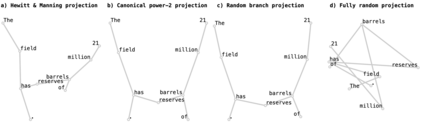
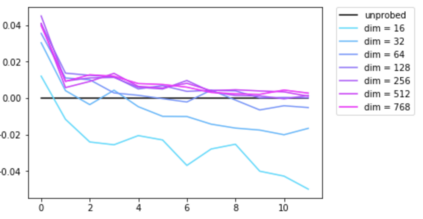
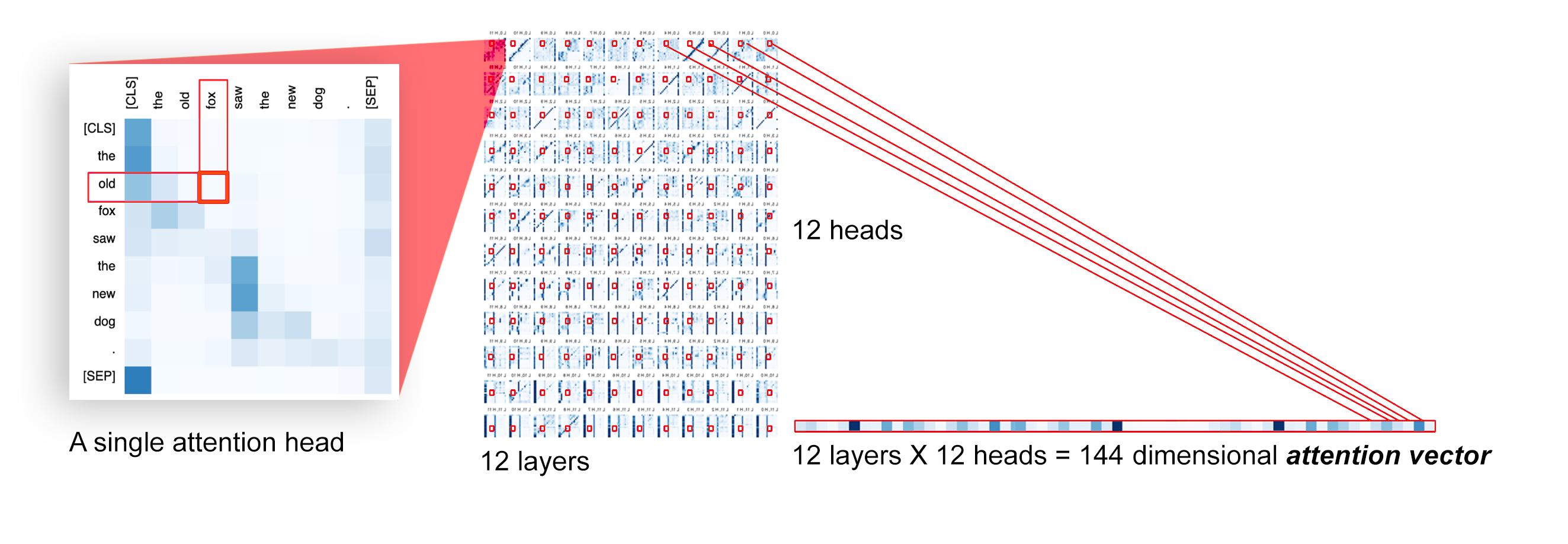
Transformer architectures show significant promise for natural language processing. Given that a single pretrained model can be fine-tuned to perform well on many different tasks, these networks appear to extract generally useful linguistic features. A natural question is how such networks represent this information internally. This paper describes qualitative and quantitative investigations of one particularly effective model, BERT. At a high level, linguistic features seem to be represented in separate semantic and syntactic subspaces. We find evidence of a fine-grained geometric representation of word senses. We also present empirical descriptions of syntactic representations in both attention matrices and individual word embeddings, as well as a mathematical argument to explain the geometry of these representations.
翻译:变换器结构显示了自然语言处理的巨大前景。鉴于单一的预演模型可以进行微调,以很好地完成许多不同的任务,这些网络似乎可以提取出普遍有用的语言特征。一个自然的问题是这类网络如何在内部代表这种信息。本文描述了对一个特别有效的模型BERT的定性和定量调查。在高层次上,语言特征似乎在不同的语义和合成亚空间中表现。我们发现了一个精细的文字感学几何表示法的证据。我们还在关注矩阵和单个单词嵌入中介绍了综合法表达法的经验性描述,以及解释这些表达法的几何性的数学论证。