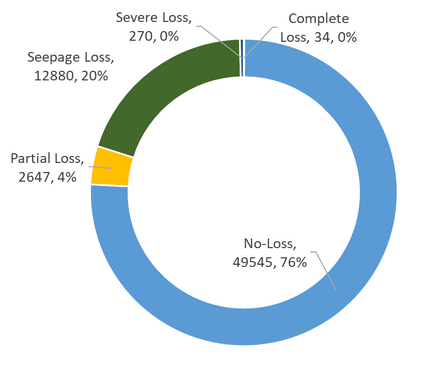
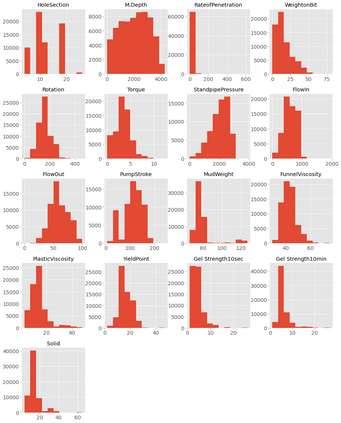
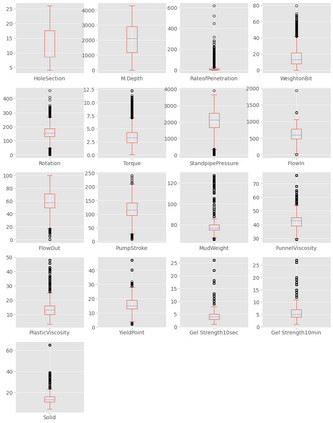
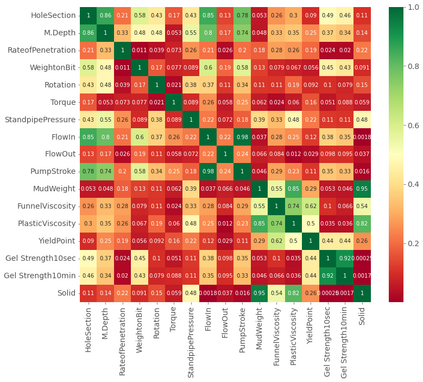
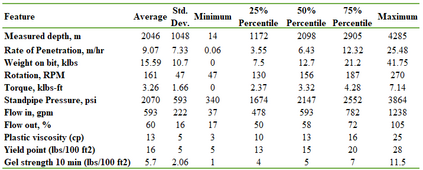
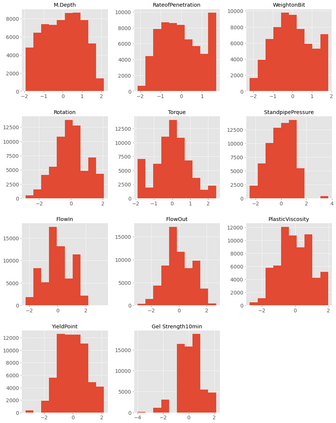
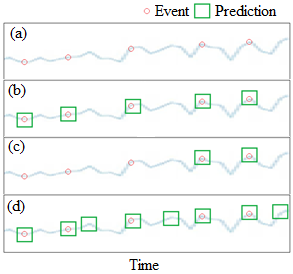
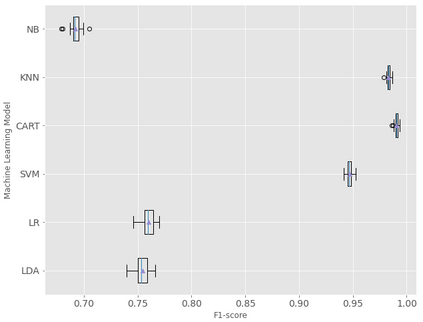
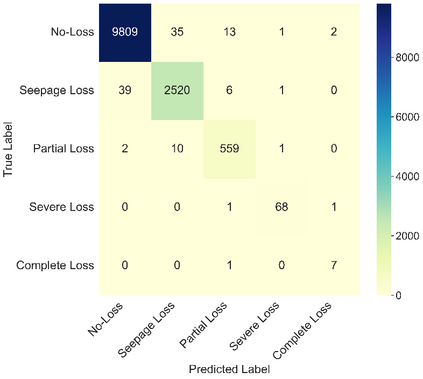
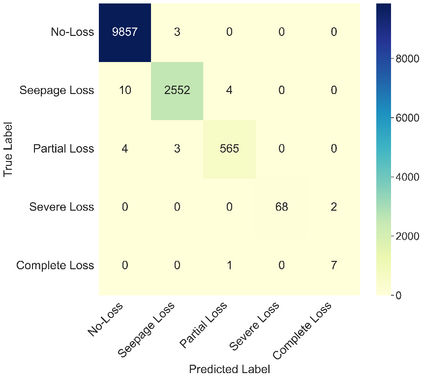
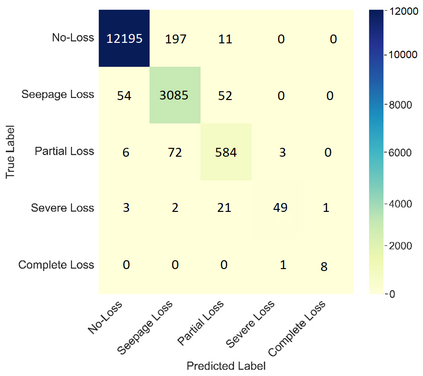
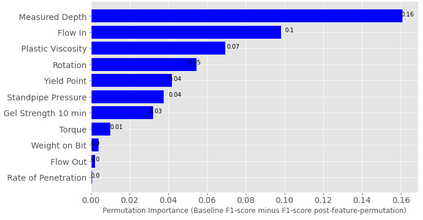
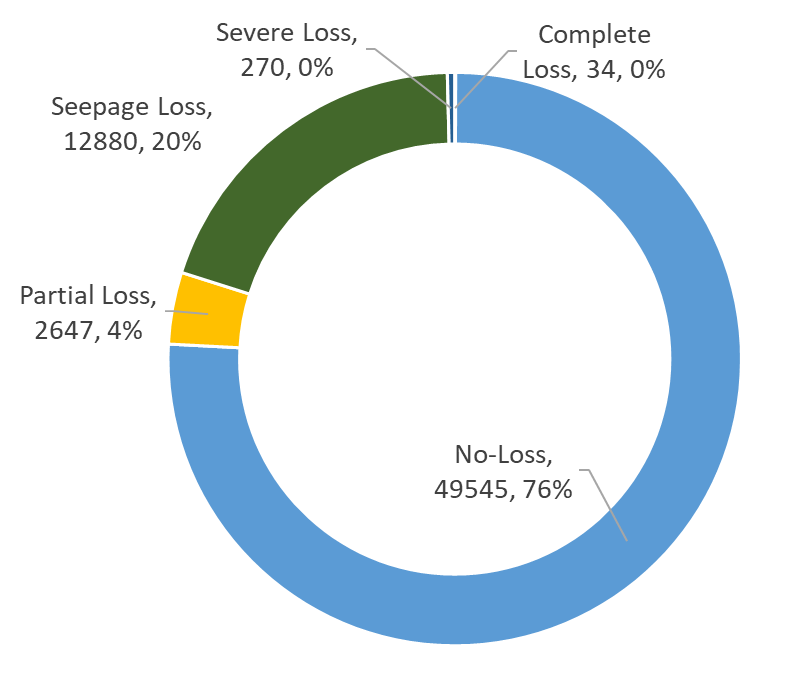
This study presents machine learning models that forecast and categorize lost circulation severity preemptively using a large class imbalanced drilling dataset. We demonstrate reproducible core techniques involved in tackling a large drilling engineering challenge utilizing easily interpretable machine learning approaches. We utilized a 65,000+ records data with class imbalance problem from Azadegan oilfield formations in Iran. Eleven of the dataset's seventeen parameters are chosen to be used in the classification of five lost circulation events. To generate classification models, we used six basic machine learning algorithms and four ensemble learning methods. Linear Discriminant Analysis (LDA), Logistic Regression (LR), Support Vector Machines (SVM), Classification and Regression Trees (CART), k-Nearest Neighbors (KNN), and Gaussian Naive Bayes (GNB) are the six fundamental techniques. We also used bagging and boosting ensemble learning techniques in the investigation of solutions for improved predicting performance. The performance of these algorithms is measured using four metrics: accuracy, precision, recall, and F1-score. The F1-score weighted to represent the data imbalance is chosen as the preferred evaluation criterion. The CART model was found to be the best in class for identifying drilling fluid circulation loss events with an average weighted F1-score of 0.9904 and standard deviation of 0.0015. Upon application of ensemble learning techniques, a Random Forest ensemble of decision trees showed the best predictive performance. It identified and classified lost circulation events with a perfect weighted F1-score of 1.0. Using Permutation Feature Importance (PFI), the measured depth was found to be the most influential factor in accurately recognizing lost circulation events while drilling.
翻译:这项研究展示了机器学习模型,用大型分类不平衡的钻探数据集来预先预测和分类失去的循环强度。我们展示了利用易于解释的机器学习方法应对大型钻探工程挑战的可复制的核心技术。我们使用了伊朗Azadegan油田形成过程中的65 000+记录数据,而伊朗的Azadegan油田形成过程中出现了阶级不平衡问题。选择了数据集的17个参数中的11个参数,用于对5个丢失的循环事件进行分类。为了生成分类模型,我们使用了6个基本机器学习算法和4个连数性学习方法。线性分辨分析(LDA)、物流回归(LRL)、支持矢量计算(SVM)、分类和回归(SVM)、分类和回归树(KNN)、KNNN(KNN)和Gaussian Naive Bayes (GNB),这是六种基本技术。我们还使用了谷分解和增量学习技术来改进预测业绩。这些算法的性能用4度分析法测量:精确性、测算、测量和F1-AAR-R8的精度的精度的精度结构,用最精度的精度的精度计算, 以显示的精度计算,以显示的精度的精度的精度的精度数据流流流流数据显示的精度的精度的精度计算。