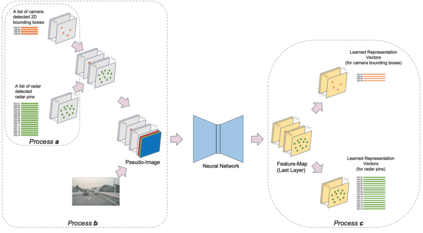
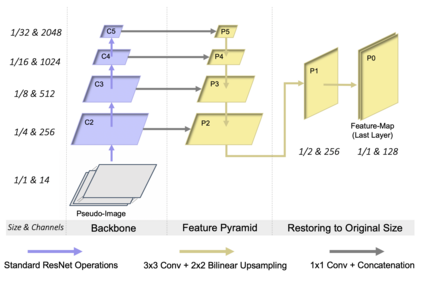
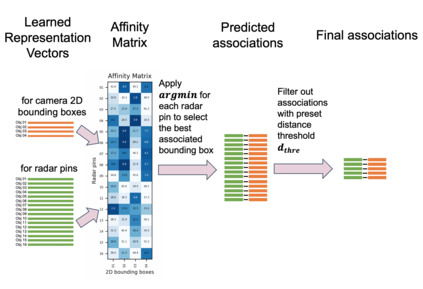
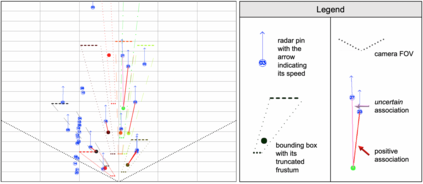
Radars and cameras are mature, cost-effective, and robust sensors and have been widely used in the perception stack of mass-produced autonomous driving systems. Due to their complementary properties, outputs from radar detection (radar pins) and camera perception (2D bounding boxes) are usually fused to generate the best perception results. The key to successful radar-camera fusion is the accurate data association. The challenges in the radar-camera association can be attributed to the complexity of driving scenes, the noisy and sparse nature of radar measurements, and the depth ambiguity from 2D bounding boxes. Traditional rule-based association methods are susceptible to performance degradation in challenging scenarios and failure in corner cases. In this study, we propose to address radar-camera association via deep representation learning, to explore feature-level interaction and global reasoning. Additionally, we design a loss sampling mechanism and an innovative ordinal loss to overcome the difficulty of imperfect labeling and to enforce critical human-like reasoning. Despite being trained with noisy labels generated by a rule-based algorithm, our proposed method achieves a performance of 92.2% F1 score, which is 11.6% higher than the rule-based teacher. Moreover, this data-driven method also lends itself to continuous improvement via corner case mining.
翻译:雷达和相机是成熟、具有成本效益和稳健的传感器,并被广泛用于大规模生产的自主驱动系统感知堆堆积体中。由于它们的互补性,雷达探测(雷达针)和相机感知(2D捆绑盒)的产出通常被结合,以产生最佳的感知结果。成功的雷达-摄像机融合的关键是准确的数据联系。雷达-摄像机协会的挑战可以归因于驾驶场的复杂性、雷达测量的杂乱和稀疏性质以及2D捆绑盒的深度模糊性。传统的基于规则的联系方法很容易在挑战性情景和角落失败的情况下出现性能退化。在本研究中,我们提议通过深层的演示学习解决雷达-摄像机联系问题,探索地貌层面的互动和全球推理。此外,我们设计了损失取样机制和创新性或短期损失机制,以克服不完善标签的困难和执行关键的人类推理。尽管我们接受基于规则的算法所产生的噪音标签培训,但我们提出的方法达到了92.2分F1分的性能,该分数比基于规则的教师本身高出11.6 %。此外,这一数据也以不断改进的方式改进。