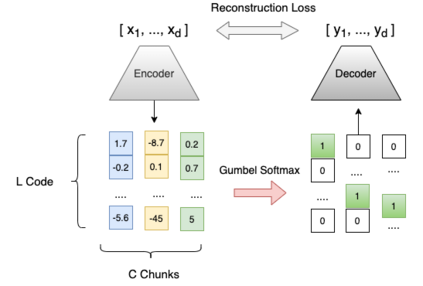
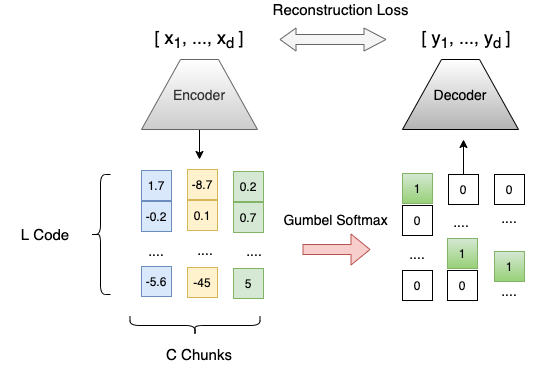
We propose a Composite Code Sparse Autoencoder (CCSA) approach for Approximate Nearest Neighbor (ANN) search of document representations based on Siamese-BERT models. In Information Retrieval (IR), the ranking pipeline is generally decomposed in two stages: the first stage focus on retrieving a candidate set from the whole collection. The second stage re-ranks the candidate set by relying on more complex models. Recently, Siamese-BERT models have been used as first stage ranker to replace or complement the traditional bag-of-word models. However, indexing and searching a large document collection require efficient similarity search on dense vectors and this is why ANN techniques come into play. Since composite codes are naturally sparse, we first show how CCSA can learn efficient parallel inverted index thanks to an uniformity regularizer. Second, CCSA can be used as a binary quantization method and we propose to combine it with the recent graph based ANN techniques. Our experiments on MSMARCO dataset reveal that CCSA outperforms IVF with product quantization. Furthermore, CCSA binary quantization is beneficial for the index size, and memory usage for the graph-based HNSW method, while maintaining a good level of recall and MRR. Third, we compare with recent supervised quantization methods for image retrieval and find that CCSA is able to outperform them.
翻译:我们建议采用复合代码 Sprass Autencoder (CCSA) 方法, 用于根据Siamese- BERT 模型, 近距离邻居( ANN) 搜索基于 Siamese- BERT 模型的文件代表。 在信息检索( IR) 中, 排名管道一般分解分为两个阶段: 第一阶段侧重于检索整个收藏的候选数据集。 第二阶段可以使用更复杂的模型重新排序候选人。 最近, SAamese- BERT 模型被用作第一阶段排名器, 以取代或补充传统的词包模型。 然而, 大量文件收藏的索引和搜索需要对密度矢量的大型文件采集进行有效的类似搜索, 这也是为什么ANNN技术开始运行的原因。 由于复合代码自然稀释, 我们首先展示了 CSA 如何通过统一校正对索引学习有效平行索引的方法。 其次, CCSA 可以用作基于 ANN 的最新图表, 我们关于MSMAR 数据集的实验显示, CSA 超越了 IVF 格式, 和 CRO 类 CRA 的精准缩略缩缩图, 。