【论文推荐】最新八篇图像检索相关论文—三元组、深度特征图、判别式、卷积特征聚合、视觉-关系知识图谱、大规模图像检索
【导读】既昨天推出七篇图像检索(Image Retrieval)文章,专知内容组今天又推出最近八篇图像检索相关文章,为大家进行介绍,欢迎查看!
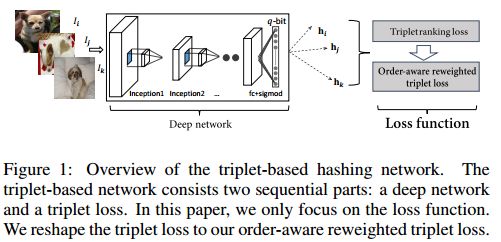
1. Improving Deep Binary Embedding Networks by Order-aware Reweighting of Triplets(通过对三元组阶感知重加权来提高深层二进制嵌入网络)
作者:Jikai Chen,Hanjiang Lai,Libing Geng,Yan Pan
机构:Sun Yat-sen University
摘要:In this paper, we focus on triplet-based deep binary embedding networks for image retrieval task. The triplet loss has been shown to be most effective for the ranking problem. However, most of the previous works treat the triplets equally or select the hard triplets based on the loss. Such strategies do not consider the order relations, which is important for retrieval task. To this end, we propose an order-aware reweighting method to effectively train the triplet-based deep networks, which up-weights the important triplets and down-weights the uninformative triplets. First, we present the order-aware weighting factors to indicate the importance of the triplets, which depend on the rank order of binary codes. Then, we reshape the triplet loss to the squared triplet loss such that the loss function will put more weights on the important triplets. Extensive evaluations on four benchmark datasets show that the proposed method achieves significant performance compared with the state-of-the-art baselines.
期刊:arXiv, 2018年4月17日
网址:
http://www.zhuanzhi.ai/document/496d85738cf7d00209ec7b7690e33371
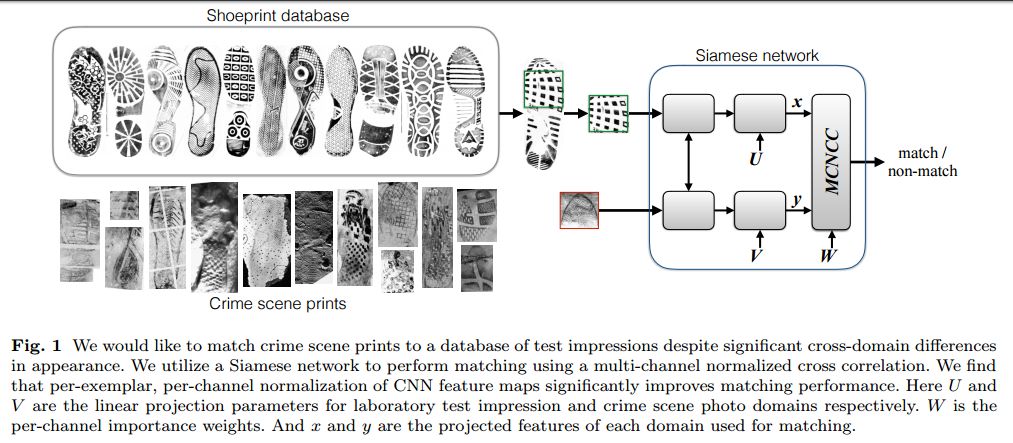
2.Cross-Domain Image Matching with Deep Feature Maps(利用深度特征图进行跨域图像匹配)
作者:AJ Piergiovanni,Michael S. Ryoo
摘要:We investigate the problem of automatically determining what type of shoe left an impression found at a crime scene. This recognition problem is made difficult by the variability in types of crime scene evidence (ranging from traces of dust or oil on hard surfaces to impressions made in soil) and the lack of comprehensive databases of shoe outsole tread patterns. We find that mid-level features extracted by pre-trained convolutional neural nets are surprisingly effective descriptors for this specialized domains. However, the choice of similarity measure for matching exemplars to a query image is essential to good performance. For matching multi-channel deep features, we propose the use of multi-channel normalized cross-correlation and analyze its effectiveness. Our proposed metric significantly improves performance in matching crime scene shoeprints to laboratory test impressions. We also show its effectiveness in other cross-domain image retrieval problems: matching facade images to segmentation labels and aerial photos to map images. Finally, we introduce a discriminatively trained variant and fine-tune our system through our proposed metric, obtaining state-of-the-art performance.
期刊:arXiv, 2018年4月7日
网址:
http://www.zhuanzhi.ai/document/e1e80df25ffc1551dc039baf9082ca41
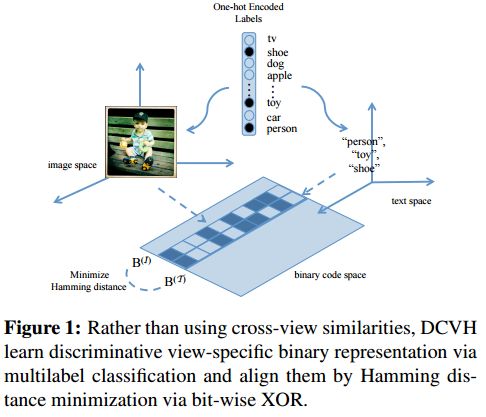
3.Discriminative Cross-View Binary Representation Learning(判别式的跨视图二进制表示学习)
作者:Liu Liu,Hairong Qi
机构:University of Tennessee
摘要:Learning compact representation is vital and challenging for large scale multimedia data. Cross-view/cross-modal hashing for effective binary representation learning has received significant attention with exponentially growing availability of multimedia content. Most existing cross-view hashing algorithms emphasize the similarities in individual views, which are then connected via cross-view similarities. In this work, we focus on the exploitation of the discriminative information from different views, and propose an end-to-end method to learn semantic-preserving and discriminative binary representation, dubbed Discriminative Cross-View Hashing (DCVH), in light of learning multitasking binary representation for various tasks including cross-view retrieval, image-to-image retrieval, and image annotation/tagging. The proposed DCVH has the following key components. First, it uses convolutional neural network (CNN) based nonlinear hashing functions and multilabel classification for both images and texts simultaneously. Such hashing functions achieve effective continuous relaxation during training without explicit quantization loss by using Direct Binary Embedding (DBE) layers. Second, we propose an effective view alignment via Hamming distance minimization, which is efficiently accomplished by bit-wise XOR operation. Extensive experiments on two image-text benchmark datasets demonstrate that DCVH outperforms state-of-the-art cross-view hashing algorithms as well as single-view image hashing algorithms. In addition, DCVH can provide competitive performance for image annotation/tagging.
期刊:arXiv, 2018年4月4日
网址:
http://www.zhuanzhi.ai/document/b2bb298a19ccc877233e7df1cd7314e3
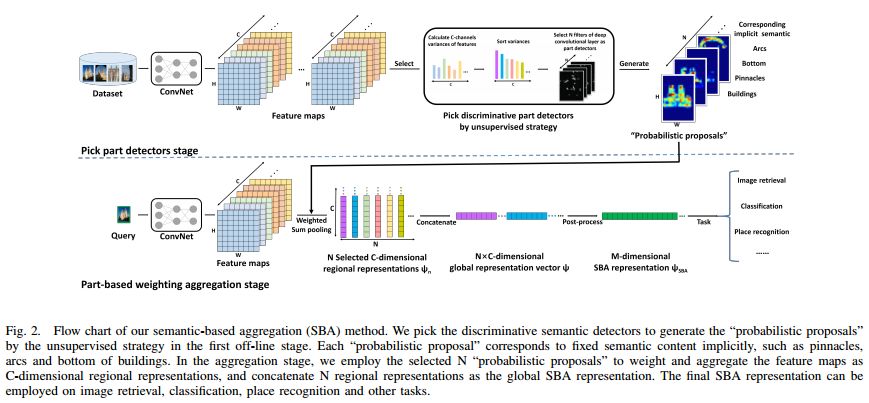
4.Unsupervised Semantic-based Aggregation of Deep Convolutional Features(无监督的基于语义的深层卷积特征聚合)
作者:Jian Xu,Chunheng Wang,Chengzuo Qi,Cunzhao Shi,Baihua Xiao
摘要:In this paper, we propose a simple but effective semantic-based aggregation (SBA) method. The proposed SBA utilizes the discriminative filters of deep convolutional layers as semantic detectors. Moreover, we propose the effective unsupervised strategy to select some semantic detectors to generate the "probabilistic proposals", which highlight certain discriminative pattern of objects and suppress the noise of background. The final global SBA representation could then be acquired by aggregating the regional representations weighted by the selected "probabilistic proposals" corresponding to various semantic content. Our unsupervised SBA is easy to generalize and achieves excellent performance on various tasks. We conduct comprehensive experiments and show that our unsupervised SBA outperforms the state-of-the-art unsupervised and supervised aggregation methods on image retrieval, place recognition and cloud classification.
期刊:arXiv, 2018年4月3日
网址:
http://www.zhuanzhi.ai/document/d7c60fd0bc1f5c877985afd5c9af6851
5.Iterative Manifold Embedding Layer Learned by Incomplete Data for Large-scale Image Retrieval(通过不完整的数据进行大规模图像检索的迭代流形嵌入层)
作者:Jian Xu,Chunheng Wang,Chengzuo Qi,Cunzhao Shi,Baihua Xiao
摘要:Existing manifold learning methods are not appropriate for image retrieval task, because most of them are unable to process query image and they have much additional computational cost especially for large scale database. Therefore, we propose the iterative manifold embedding (IME) layer, of which the weights are learned off-line by unsupervised strategy, to explore the intrinsic manifolds by incomplete data. On the large scale database that contains 27000 images, IME layer is more than 120 times faster than other manifold learning methods to embed the original representations at query time. We embed the original descriptors of database images which lie on manifold in a high dimensional space into manifold-based representations iteratively to generate the IME representations in off-line learning stage. According to the original descriptors and the IME representations of database images, we estimate the weights of IME layer by ridge regression. In on-line retrieval stage, we employ the IME layer to map the original representation of query image with ignorable time cost (2 milliseconds). We experiment on five public standard datasets for image retrieval. The proposed IME layer significantly outperforms related dimension reduction methods and manifold learning methods. Without post-processing, Our IME layer achieves a boost in performance of state-of-the-art image retrieval methods with post-processing on most datasets, and needs less computational cost.
期刊:arXiv, 2018年4月3日
网址:
http://www.zhuanzhi.ai/document/ad75fdf1da9a2cec65a074c409389784
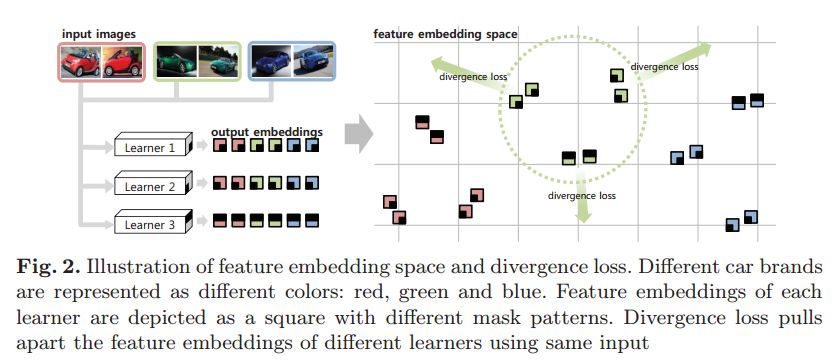
6.Attention-based Ensemble for Deep Metric Learning(深度度量学习的基于注意力的集成)
作者:Wonsik Kim,Bhavya Goyal,Kunal Chawla,Jungmin Lee,Keunjoo Kwon
摘要:Recently, ensemble has been applied to deep metric learning to yield state-of-the-art results. Deep metric learning aims to learn deep neural networks for feature embeddings, distances of which satisfy given constraint. In deep metric learning, ensemble takes average of distances learned by multiple learners. As one important aspect of ensemble, the learners should be diverse in their feature embeddings. To this end, we propose an attention-based ensemble, which uses multiple attention masks, so that each learner can attend to different parts of the object. We also propose a divergence loss, which encourages diversity among the learners. The proposed method is applied to the standard benchmarks of deep metric learning and experimental results show that it outperforms the state-of-the-art methods by a significant margin on image retrieval tasks.
期刊:arXiv, 2018年4月2日
网址:
http://www.zhuanzhi.ai/document/cb4ba2be7c5c53bce3b136078eeb5983
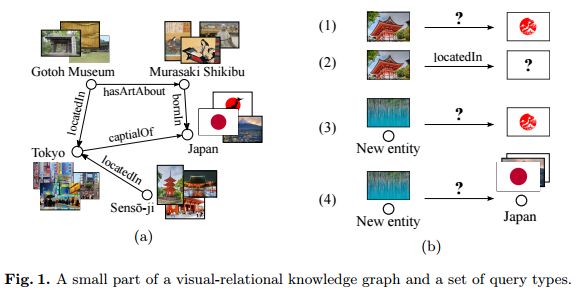
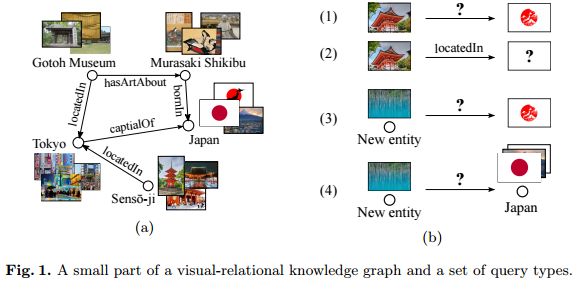
7.Representation Learning for Visual-Relational Knowledge Graphs(视觉-关系知识图谱的表示学习)
作者:Daniel Oñoro-Rubio,Mathias Niepert,Alberto García-Durán,Roberto González,Roberto J. López-Sastre
摘要:A visual-relational knowledge graph (KG) is a multi-relational graph whose entities are associated with images. We introduce ImageGraph, a KG with 1,330 relation types, 14,870 entities, and 829,931 images. Visual-relational KGs lead to novel probabilistic query types where images are treated as first-class citizens. Both the prediction of relations between unseen images and multi-relational image retrieval can be formulated as query types in a visual-relational KG. We approach the problem of answering such queries with a novel combination of deep convolutional networks and models for learning knowledge graph embeddings. The resulting models can answer queries such as "How are these two unseen images related to each other?" We also explore a zero-shot learning scenario where an image of an entirely new entity is linked with multiple relations to entities of an existing KG. The multi-relational grounding of unseen entity images into a knowledge graph serves as the description of such an entity. We conduct experiments to demonstrate that the proposed deep architectures in combination with KG embedding objectives can answer the visual-relational queries efficiently and accurately.
期刊:arXiv, 2018年3月31日
网址:
http://www.zhuanzhi.ai/document/3ecb0361c5d0c4f6f94004f60b68c970
8.Revisiting Oxford and Paris: Large-Scale Image Retrieval Benchmarking(重访牛津和巴黎:大规模的图像检索的基准)
作者:Filip Radenović,Ahmet Iscen,Giorgos Tolias,Yannis Avrithis,Ondřej Chum
摘要:In this paper we address issues with image retrieval benchmarking on standard and popular Oxford 5k and Paris 6k datasets. In particular, annotation errors, the size of the dataset, and the level of challenge are addressed: new annotation for both datasets is created with an extra attention to the reliability of the ground truth. Three new protocols of varying difficulty are introduced. The protocols allow fair comparison between different methods, including those using a dataset pre-processing stage. For each dataset, 15 new challenging queries are introduced. Finally, a new set of 1M hard, semi-automatically cleaned distractors is selected. An extensive comparison of the state-of-the-art methods is performed on the new benchmark. Different types of methods are evaluated, ranging from local-feature-based to modern CNN based methods. The best results are achieved by taking the best of the two worlds. Most importantly, image retrieval appears far from being solved.

期刊:arXiv, 2018年3月30日
网址:
http://www.zhuanzhi.ai/document/73985857b11fb674af505ac9ec53de54
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
投稿&广告&商务合作:fangquanyi@gmail.com
点击“阅读原文”,使用专知


