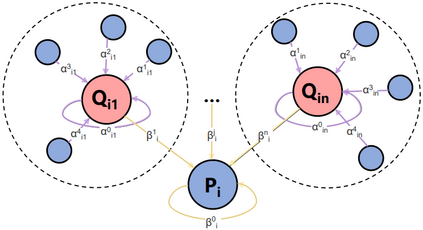
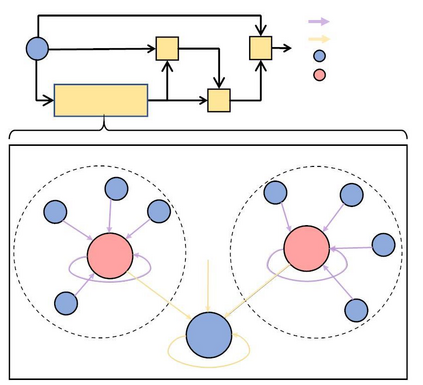
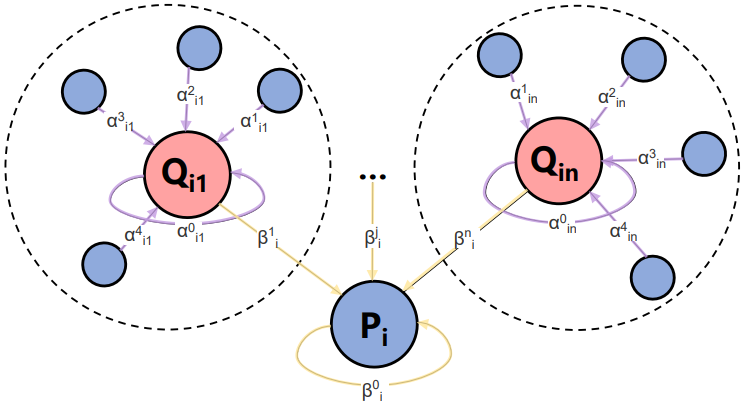
Recently, retrieval models based on dense representations are dominant in passage retrieval tasks, due to their outstanding ability in terms of capturing semantics of input text compared to the traditional sparse vector space models. A common practice of dense retrieval models is to exploit a dual-encoder architecture to represent a query and a passage independently. Though efficient, such a structure loses interaction between the query-passage pair, resulting in inferior accuracy. To enhance the performance of dense retrieval models without loss of efficiency, we propose a GNN-encoder model in which query (passage) information is fused into passage (query) representations via graph neural networks that are constructed by queries and their top retrieved passages. By this means, we maintain a dual-encoder structure, and retain some interaction information between query-passage pairs in their representations, which enables us to achieve both efficiency and efficacy in passage retrieval. Evaluation results indicate that our method significantly outperforms the existing models on MSMARCO, Natural Questions and TriviaQA datasets, and achieves the new state-of-the-art on these datasets.
翻译:最近,基于密度表示的检索模型在传输检索任务中占据了主导地位,因为与传统的稀有矢量空间模型相比,这些模型在捕捉输入文字的语义与传统稀有矢量空间模型相比,在获取输入文字的语义方面具有突出能力。密集检索模型的常见做法是利用双编码结构独立代表查询和通道。虽然这种结构效率很高,但会失去查询通道对对口之间的交互作用,从而导致精确度低下。为了提高密集检索模型的性能,同时又不丧失效率,我们提议采用GNNN-encoder模型,其中查询(访问)信息通过通过通过通过通过查询及其顶层检索通道建造的图形神经网络整合为传输(查询)表达。我们通过这一方法,维持了双编码结构,并保留了它们所代表的对口查询对口之间的一些互动信息,从而使我们能够在传输通道检索方面实现效率和效能。评价结果表明,我们的方法大大超越了MSMARCO、自然问题和TriviaQA数据集的现有模型,并实现了这些数据集上的新状态。