强化学习族谱
https://github.com/tigerneil/deep-reinforcement-learning-family
deep-reinforcement-learning-records

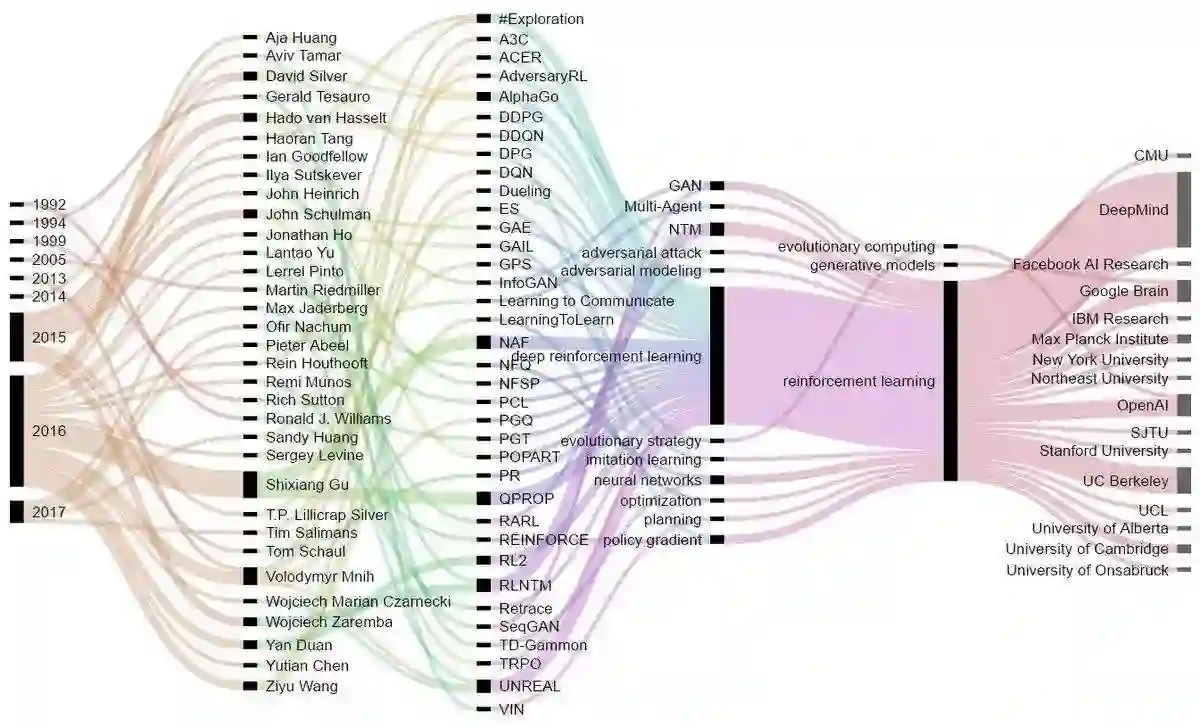
Explicitly show the relationships between various techniques of deep reinforcement learning methods.
Dedicated for learning and researching on DRL.
Policy gradient methods
Equivalence Between Policy Gradients and Soft Q-Learning
Trust Region Policy Optimization
Reinforcement Learning with Deep Energy-Based Policies
Q-PROP: SAMPLE-EFFICIENT POLICY GRADIENT WITH AN OFF-POLICY CRITIC
Interpolated Policy Gradient: Merging On-Policy and Off-Policy Gradient Estimation for Deep Reinforcement Learning 1 Jun 2017
Explorations in DRL
Incentivizing Exploration In Reinforcement Learning With Deep Predictive Models
EX2: Exploration with Exemplar Models for Deep Reinforcement Learning
Actor-Critic methods
The Reactor: A Sample-Efficient Actor-Critic Architecture 15 Apr 2017
SAMPLE EFFICIENT ACTOR-CRITIC WITH EXPERIENCE REPLAY
REINFORCEMENT LEARNING WITH UNSUPERVISED AUXILIARY TASKS
Continuous control with deep reinforcement learning
Connection with other methods
Connecting Generative Adversarial Networks and Actor-Critic Methods
Connecting value and policy methods
Bridging the Gap Between Value and Policy Based Reinforcement Learning
Policy gradient and Q-learning
Unifying
Multi-step Reinforcement Learning: A Unifying Algorithm
Faster DRL
Neural Episodic Control
Apply RL to other domains
TUNING RECURRENT NEURAL NETWORKS WITH REINFORCEMENT LEARNING
Multiagent Settings
Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments 7 Jun 2017
Multiagent Bidirectionally-Coordinated Nets for Learning to Play StarCraft Combat Games 29 Mar 2017



