
题目: Pre-training Tasks for Embedding-based Large-scale Retrieval
摘要:
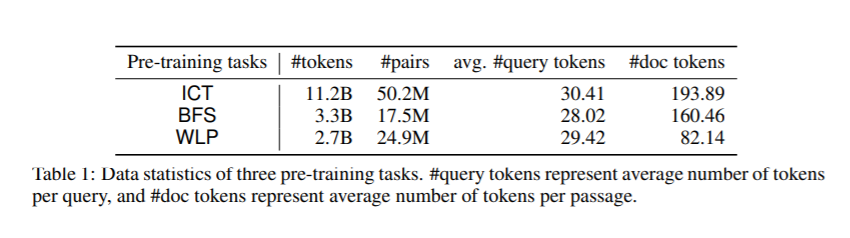
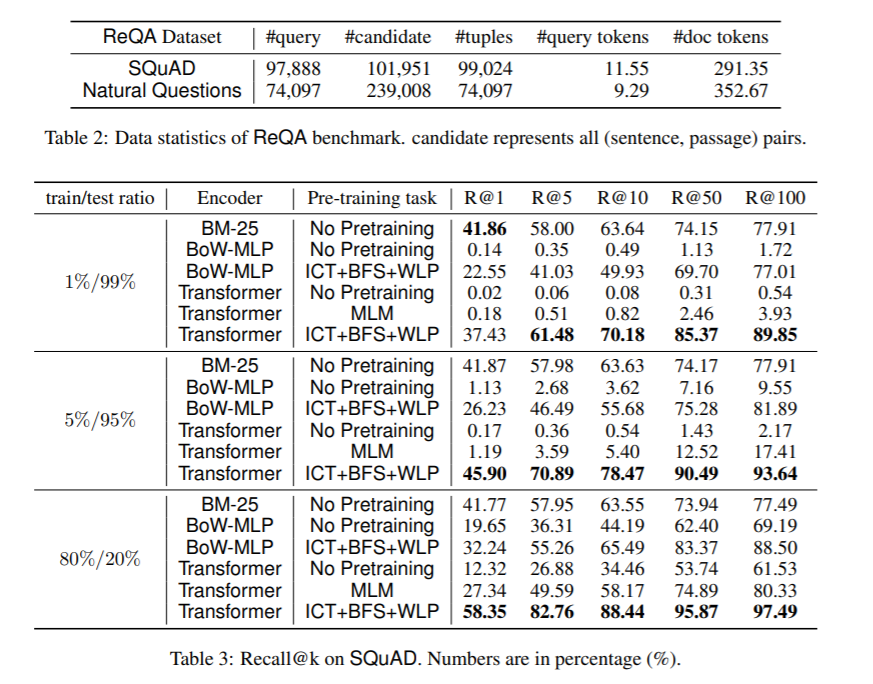
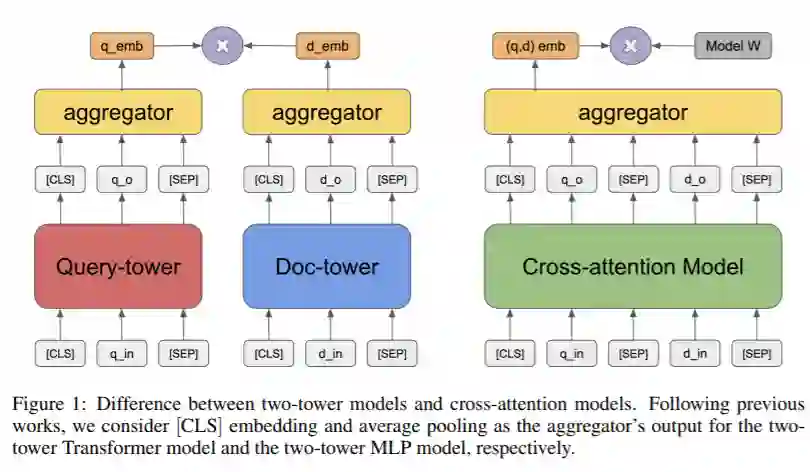
我们考虑大型查询文档检索问题:给定一个查询(例如,一个问题),从大型文档语料库返回相关文档集(例如,包含答案的段落)。这个问题通常分两步解决。检索阶段首先减少解决方案空间,返回候选文档的子集。然后评分阶段重新排列文档。关键是,该检索算法不仅要求较高的查全率,而且要求具有较高的效率,能够及时返回与文档数量成次线性关系的候选对象。不像评分阶段,由于交叉注意力模型上的伯特式训练任务,最近取得了重大进展,检索阶段仍然没有得到很好的研究。以前的大部分工作依赖于经典的信息检索(IR)方法,如BM-25(令牌匹配+ TF-IDF权值)。这些模型只接受稀疏的手工特性,不能针对感兴趣的不同下游任务进行优化。本文对基于嵌入式的检索模型进行了全面的研究。我们证明了学习强嵌入式变压器模型的关键是训练前的任务集。通过充分设计分段级的预训练任务,变压器模型比广泛使用的BM-25模型以及没有变压器的嵌入模型有显著的改进。我们研究的分段式预训练任务包括Inverse Close Task(ICT)、Body First Selection(BFS)、Wiki Link Prediction(WLP)以及三者的结合。
成为VIP会员查看完整内容

相关内容

信息检索(
Information Retrieval )指信息按一定的方式组织起来,并根据信息用户的需要找出有关的信息的过程和技术。信息检索的目标:准确、及时、全面的获取所需信息。
专知会员服务
32+阅读 · 2020年2月21日
专知会员服务
45+阅读 · 2020年2月14日
微软发布DialoGPT预训练语言模型,论文与代码 Large-Scale Generative Pre-training for Conversational Response Generation
专知会员服务
28+阅读 · 2019年11月8日



相关VIP内容
专知会员服务
32+阅读 · 2020年2月21日
专知会员服务
45+阅读 · 2020年2月14日
微软发布DialoGPT预训练语言模型,论文与代码 Large-Scale Generative Pre-training for Conversational Response Generation
专知会员服务
28+阅读 · 2019年11月8日
相关资讯
相关论文