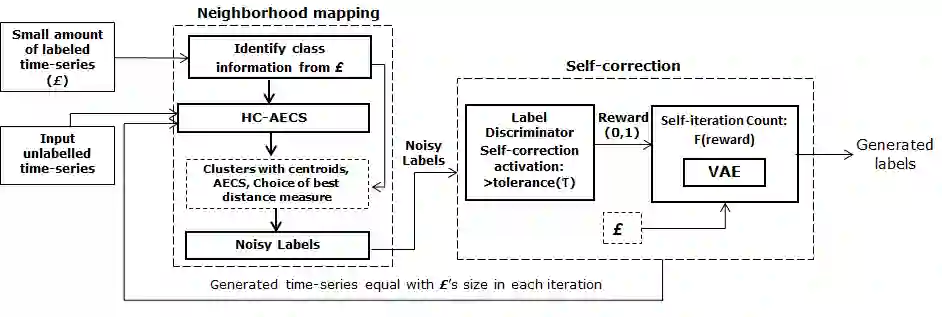
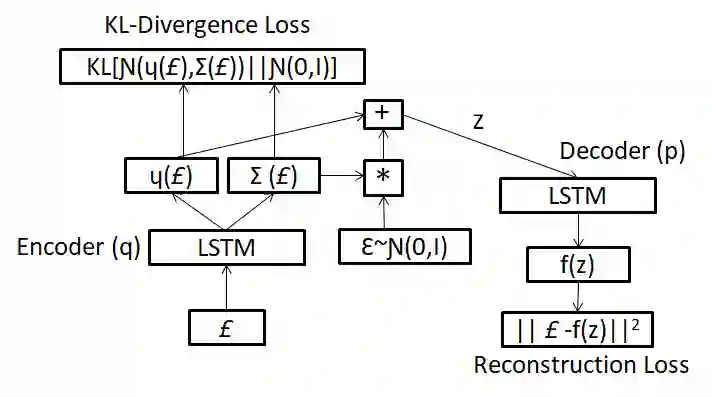
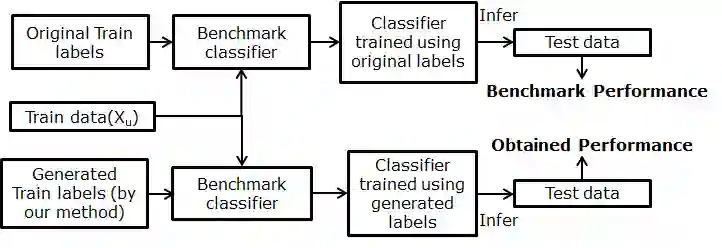
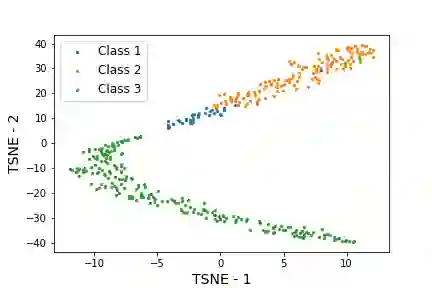
Time-series generated by end-users, edge devices, and different wearables are mostly unlabelled. We propose a method to auto-generate labels of un-labelled time-series, exploiting very few representative labelled time-series. Our method is based on representation learning using Auto Encoded Compact Sequence (AECS) with a choice of best distance measure. It performs self-correction in iterations, by learning latent structure, as well as synthetically boosting representative time-series using Variational-Auto-Encoder (VAE) to improve the quality of labels. We have experimented with UCR and UCI archives, public real-world univariate, multivariate time-series taken from different application domains. Experimental results demonstrate that the proposed method is very close to the performance achieved by fully supervised classification. The proposed method not only produces close to benchmark results but outperforms the benchmark performance in some cases.
翻译:由终端用户、边缘装置和不同磨损器生成的时间序列大多没有标签。 我们提出了一个自动生成无标签时间序列标签的方法, 利用极少数有代表性的标记时间序列。 我们的方法是基于使用自动编码契约序列( AECS) 进行代议学习, 选择了最佳距离测量。 它在迭代中进行自我校正, 学习潜伏结构, 以及使用变式自动电子代号( VAE) 合成增强代议时间序列, 以提高标签的质量。 我们实验了 UCR 和 UCI 档案, 公共实体非主流代议, 从不同应用区域获取的多变时间序列。 实验结果显示, 拟议的方法非常接近通过完全监督的分类实现的性能。 拟议的方法不仅接近于基准结果, 也超过了某些情况下的基准性能 。