论文浅尝 | Reinforcement Learning for Relation Classification
论文链接:http://aihuang.org/p/papers/AAAI2018Denoising.pdf
来源:AAAI 2018
Motivation
Distant Supervision 是一种常用的生成关系分类训练样本的方法,它通过将知识库与非结构化文本对齐来自动构建大量训练样本,减少模型对人工标注数据的依赖。但是这样标注出的数据会有很多噪音,例如,如果Obama和United States在知识库中的关系是 BornIn,那么“Barack Obama is the 44th President of the United States.”这样的句子也会被标注为BornIn关系。
为了减少训练样本中的噪音,本文希望训练一个模型来对样本进行筛选,以便构造一个噪音较小的数据集。模型在对样本进行筛选时,无法直接判断每条样本的好坏,只能在筛选完以后判断整个数据集的质量,这种 delayed reward 的情形很适合用强化学习来解决。
Model
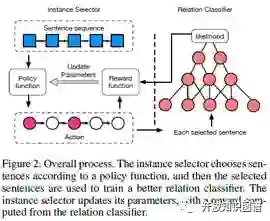
模型框架如图所示,左边是基于强化学习的 Instance Selector,右边是经典的基于 CNN 的 Relation Classifier。Instance Selector 根据 Policy function 对样本逐个筛选,每个样本都可以执行“选”或“不选”两种 Action,筛选完以后会生成一个新的数据集,我们用 Relation Classifier 来评估数据集的好坏,计算出一个 reward,再使用 policy gradient 来更新 Policy function 的参数,这里的 reward 采用的是数据集中所有样本的平均 likelihood。
为了得到更多的反馈,提高训练效率,作者将样本按照实体对分成一个个 bag,每次 Instance Selector 对一个 bag 筛选完以后,都会用 Relation Classifier 对这部分数据集进行评估,并更新 Policy function 的参数。在所有 bag 训练完以后,再用筛选出的所有样本更新 Relation Classifier 的参数。
具体训练过程如下:

Experiment
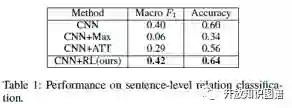
论文在 NYT 数据集上与目前主流的方法进行了比较,注意这里是 sentence-level 的分类结果,可以看到该方法取得了不错的效果。
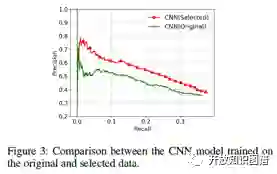
论文分别在原始数据集和筛选以后的数据集上训练了两种模型,并用 held-out evaluation 进行评估,可以看出筛选以后的数据集训练出了更好的关系分类模型。
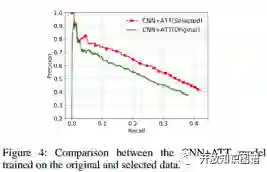
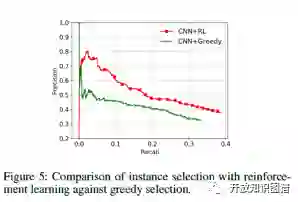
作者又比较了使用强化学习和 greedy selection 两种筛选样本的方法,强化学习的效果更好一些。
论文笔记整理:周亚林,浙江大学硕士,研究方向为知识图谱、关系抽取。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

转载须知:转载需注明来源“OpenKG.CN”、作者及原文链接。如需修改标题,请注明原标题。
点击阅读原文,进入 OpenKG 博客。




