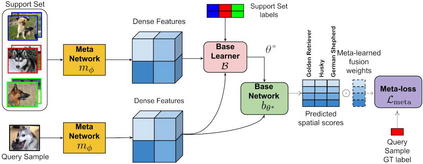
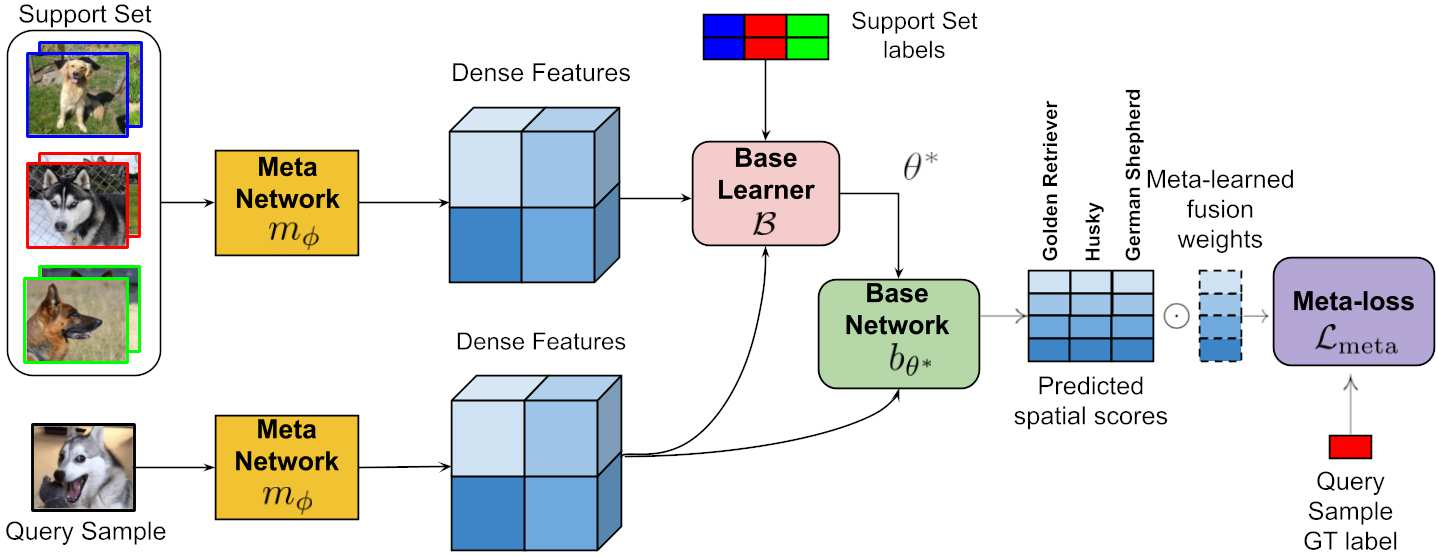
Learning in a low-data regime from only a few labeled examples is an important, but challenging problem. Recent advancements within meta-learning have demonstrated encouraging performance, in particular, for the task of few-shot classification. We propose a novel optimization-based meta-learning approach for few-shot classification. It consists of an embedding network, providing a general representation of the image, and a base learner module. The latter learns a linear classifier during the inference through an unrolled optimization procedure. We design an inner learning objective composed of (i) a robust classification loss on the support set and (ii) an entropy loss, allowing transductive learning from unlabeled query samples. By employing an efficient initialization module and a Steepest Descent based optimization algorithm, our base learner predicts a powerful classifier within only a few iterations. Further, our strategy enables important aspects of the base learner objective to be learned during meta-training. To the best of our knowledge, this work is the first to integrate both induction and transduction into the base learner in an optimization-based meta-learning framework. We perform a comprehensive experimental analysis, demonstrating the effectiveness of our approach on four few-shot classification datasets.
翻译:在低数据系统中从几个标签实例中学习是一个重要但具有挑战性的问题。在元学习中最近的进展显示了令人鼓舞的业绩,特别是在少数分类的任务方面。我们提议了一种新的基于优化的元学习方法,用于少数分类。它包括嵌入网络,对图像进行一般的描述,以及一个基础学习者模块。后者通过不滚动的优化程序在推断过程中学习线性分类器。我们设计了一个内部学习目标,包括(一) 支持集的严格分类损失,以及(二) 输入损失,允许从未标的查询样本中转学。我们的基础学习者通过使用高效初始化模块和基于原始原始优化的算法,预测只有少量的迭代内有一个强大的分类器。此外,我们的战略使得在元培训过程中能够学习基础学习者目标的重要方面得到学习。根据我们的知识,这项工作首先将引导和转换纳入基于基于优化的元学习框架的基础学习者之中。我们进行了全面的实验性分析,展示了我们四个数据分类的效用。