
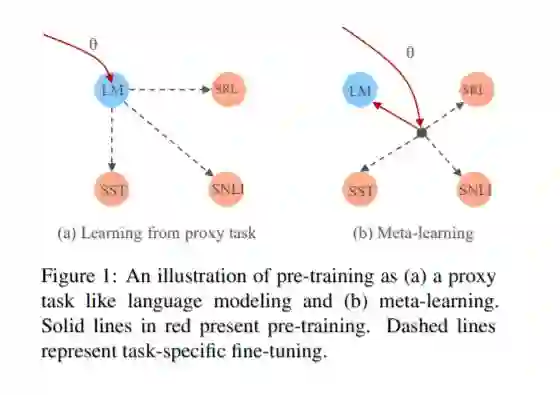
最近的研究表明,预训练文本表示能够显著提高许多自然语言处理任务的性能。训练的中心目标是学习对后续任务有用的文本表示形式。然而,现有的方法是通过最小化代理目标(如语言建模的负日志可能性)来优化的。在这项工作中,我们介绍了一个学习算法,它直接优化模型学习文本表示的能力,以有效地学习下游任务。我们证明了多任务预训练和模型不可知的元学习之间有着内在的联系。BERT中采用的标准多任务学习目标是元训练深度为零的学习算法的一个特例。我们在两种情况下研究了这个问题:无监督的预训练和有监督的预训练,不同的预训练对象验证了我们的方法的通用性。实验结果表明,我们的算法对各种下游任务进行了改进,获得了更好的初始化。
成为VIP会员查看完整内容
相关内容
专知会员服务
28+阅读 · 2020年2月12日
专知会员服务
43+阅读 · 2020年1月28日
Arxiv
7+阅读 · 2019年2月3日

相关VIP内容
专知会员服务
28+阅读 · 2020年2月12日
专知会员服务
43+阅读 · 2020年1月28日
相关资讯
相关论文
Arxiv
7+阅读 · 2019年2月3日