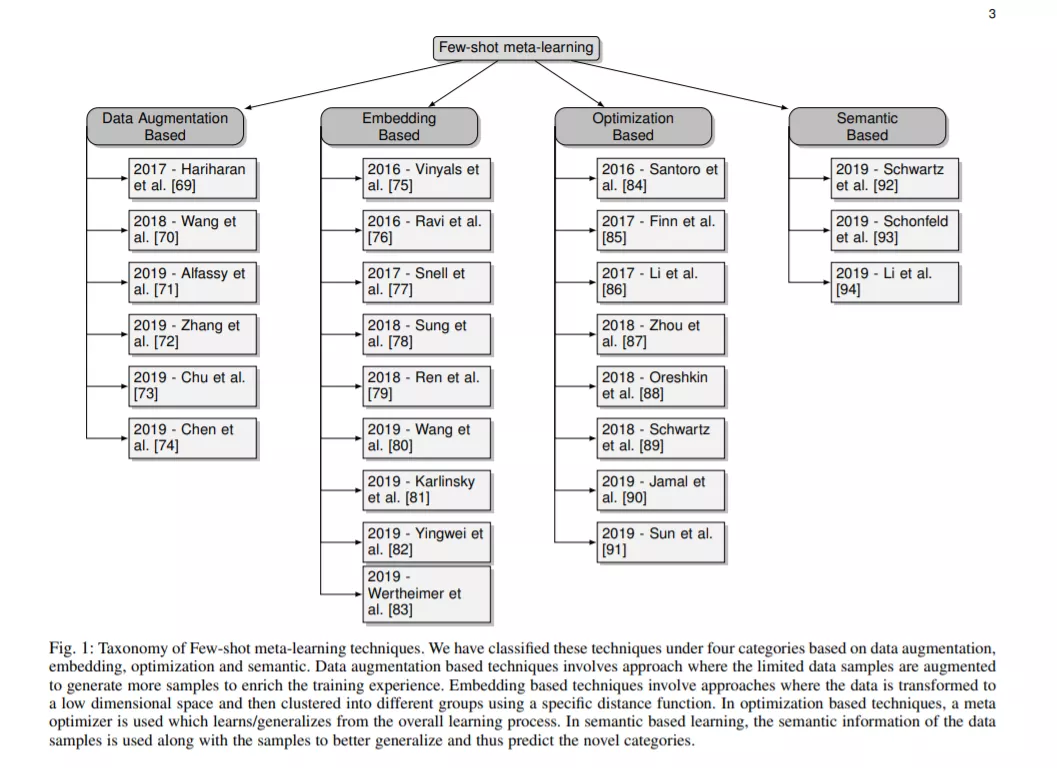
小样本学习是当前研究关注的热点。这篇论文总结了2016年到2020年的小样本元学习文章,划分为四类:基于数据增强; 基于度量学习,基于元优化; 和基于语义的。值得查看!

摘要:
在图像识别和图像分类等方面,深度神经网络的表现已经超过了人类。然而,随着各种新类别的出现,如何从有限的样本中不断扩大此类网络的学习能力,仍然是一个挑战。像元学习和/或小样本学习这样的技术表现出了良好的效果,他们可以根据先验知识学习或归纳到一个新的类别/任务。在本文中,我们研究了计算机视觉领域中现有的小样本元学习技术的方法和评价指标。我们为这些技术提供了一个分类法,并将它们分类为数据增强、嵌入、优化和基于语义的学习,用于小样本、单样本和零样本设置。然后我们描述在每个类别中所做的重要工作,并讨论他们解决从少数样本中学习的困境的方法。最后,我们在常用的基准测试数据集Omniglot和MiniImagenet上比较了这些技术,并讨论了提高这些技术性能的未来方向,从而达到超越人类的最终目标。
地址: https://www.zhuanzhi.ai/paper/8d29a5f14fcd0cc9a1aa508d072fb328
概述:
基于人工智能(AI)的系统正在成为人类生活的重要组成部分,无论是个人生活还是专业生活。我们周围都是基于人工智能的机器和应用程序,它们将使我们的生活变得更容易。例如,自动邮件过滤(垃圾邮件检测),购物网站推荐,智能手机中的社交网络等[1,2,3,4]。这一令人印象深刻的进展之所以成为可能,是因为机器或深度学习模型[5]取得了突破性的成功。机器或深度学习占据了AI领域的很大一部分。深度学习模型是建立在多层感知器与应用基于梯度的优化技术的能力。深度学习模型最常见的两个应用是:计算机视觉(CV),其目标是教会机器如何像人类一样看和感知事物;自然语言处理(NLP)和自然语言理解(NLU),它们的目标是分析和理解大量的自然语言数据。这些深度学习模型在图像识别[6,7,8]、语音识别[9,10,11,12,13]、自然语言处理与理解[14,15,16,17,18]、视频分析[19,20,21,22,23]、网络安全[24,25,26,27,28,29,30]等领域都取得了巨大的成功。机器和/或深度学习最常见的方法是监督学习,其中针对特定应用程序的大量数据样本与它们各自的标签一起被收集并形成一个数据集。该数据集分为三个部分: 训练、验证和测试。在训练阶段,将训练集和验证集的数据及其各自的标签输入模型,通过反向传播和优化,将模型归纳为一个假设。在测试阶段,将测试数据输入模型,根据导出的假设,模型预测测试数据样本的输出类别。
由于计算机和现代系统的强大能力[31,32],处理大量数据的能力已经非常出色。随着各种算法和模型的进步,深度学习已经能够赶上人类,在某些情况下甚至超过人类。AlphaGo[33]是一个基于人工智能的agent,在没有任何人类指导的情况下训练,能够击败世界围棋冠军。围棋是一种古老的棋盘游戏,被认为比国际象棋[34]复杂10倍;在另一个复杂的多人战略游戏《DOTA》中,AI-agent打败了《DOTA[35]》的人类玩家;对于图像识别和分类的任务,ResNet[6]和Inception[36,37,38]等模型能够在流行的ImageNet数据集上取得比人类更好的性能。ImageNet数据集包括超过1400万张图像,超过1000个类别[39]。
人工智能的最终目标之一是在任何给定的任务中赶上或超过人类。为了实现这一目标,必须尽量减少对大型平衡标记数据集的依赖。当前的模型在处理带有大量标记数据的任务时取得了成功的结果,但是对于其他带有标记数据很少的任务(只有少数样本),各自模型的性能显著下降。对于任何特定任务,期望大型平衡数据集是不现实的,因为由于各种类别的性质,几乎不可能跟上产生的标签数据。此外,生成标记数据集需要时间、人力等资源,而且在经济上可能非常昂贵。另一方面,人类可以快速地学习新的类或类,比如给一张奇怪动物的照片,它可以很容易地从一张由各种动物组成的照片中识别出动物。人类相对于机器的另一个优势是能够动态地学习新的概念或类,而机器必须经过昂贵的离线培训和再培训整个模型来学习新类,前提是要有标签数据可用性。研究人员和开发人员的动机是弥合人类和机器之间的鸿沟。作为这个问题的一个潜在解决方案,我们已经看到元学习[40,41,42,43,44,45,46,47,48,49,50]、小样本学习[51,52,53,54]、低资源学习[55,56,57,58]、零样本学习[59,60,61,62,63,63,64,64,65]等领域的工作在不断增加,这些领域的目标是使模型更好地推广到包含少量标记样本的新任务。
什么是小样本元学习?
在few-shot, low-shot, n-shot learning (n一般在1 - 5之间)中,其基本思想是用大量的数据样本对模型进行多类的训练,在测试过程中,模型会给定一个新的类别(也称为新集合),每个类别都有多个数据样本,一般类别数限制为5个。在元学习中,目标是泛化或学习学习过程,其中模型针对特定任务进行训练,不同分类器的函数用于新任务集。目标是找到最佳的超参数和模型权值,使模型能够轻松适应新任务而不过度拟合新任务。在元学习中,有两类优化同时运行: 一类是学习新的任务; 另一个是训练学习器。近年来,小样本学习和元学习技术引起了人们极大的兴趣。
元学习领域的早期研究工作是Yoshua和Samy Bengio[67]以及Fei-Fei Li在less -shot learning[68]中完成的。度量学习是使用的较老的技术之一,其目标是从嵌入空间中学习。将图像转换为嵌入向量,特定类别的图像聚在一起,而不同类别的图像聚在一起比较远。另一种流行的方法是数据增强,从而在有限的可用样本中产生更多的样本。目前,基于语义的方法被广泛地研究,分类仅仅基于类别的名称及其属性。这种基于语义的方法是为了解决零样本学习应用的启发。
迁移学习与自监督学习
迁移学习的总体目标是从一组任务中学习知识或经验,并将其迁移到类似领域的任务中去[95]。用于训练模型获取知识的任务有大量的标记样本,而迁移任务的标记数据相对较少(也称为微调),这不足以使模型训练和收敛到特定的任务。迁移学习技术的表现依赖于两项任务之间的相关性。在执行迁移学习时,分类层被训练用于新的任务,而模型中先前层的权值保持不变[96]。对于每一个新的任务,在我们进行迁移学习的地方,学习速率的选择和要冻结的层数都必须手工决定。与此相反,元学习技术可以相当迅速地自动适应新的任务。
自监督学习的研究近年来得到了广泛的关注[97,98,99]。自监督学习(SSL)技术的训练基于两个步骤:一是在一个预定义代理任务上进行训练,在大量的未标记数据样本上进行训练;第二,学习到的模型参数用于训练或微调主要下游任务的模型。元学习或小样本学习技术背后的理念与自监督学习非常相似,自监督学习是利用先前的知识,识别或微调一个新的任务。研究表明,自监督学习可以与小样本学习一起使用,以提高模型对新类别的表现[100,101]。
方法体系组织:
元学习、小样本学习、低资源学习、单样本学习、零样本学习等技术的主要目标是通过基于先验知识或经验的迭代训练,使深度学习模型从少量样本中学习能泛化到新类别。先验知识是在包含大量样本的带标签数据集上训练样本,然后利用这些知识在有限样本下识别新的任务而获得的知识。因此,在本文中,我们将所有这些技术结合在了小样本体系下。由于这些技术没有预定义的分类,我们将这些方法分为四大类: 基于数据增强; 基于度量学习,基于元优化; 和基于语义的(如图1所示)。基于数据增强的技术非常流行,其思想是通过扩充最小可用样本和生成更多样化的样本来训练模型来扩展先验知识。在基于嵌入的技术中,数据样本被转换为另一个低级维,然后根据这些嵌入之间的距离进行分类。在基于优化的技术中,元优化器用于在初始训练期间更好地泛化模型,从而可以更好地预测新任务。基于语义的技术是将数据的语义与模型的先验知识一起用于学习或优化新的类别。