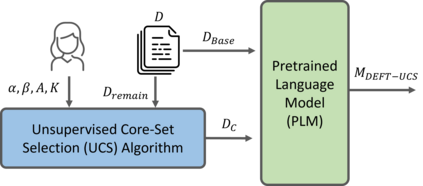
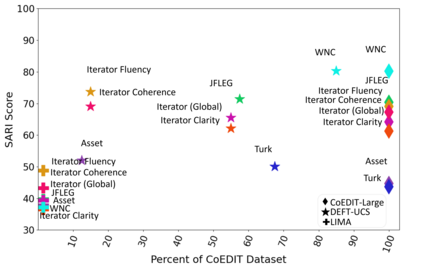
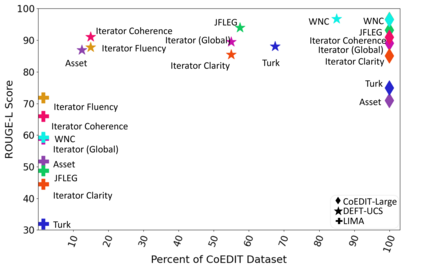
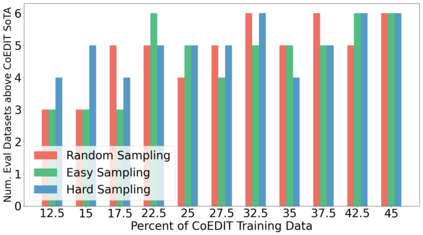
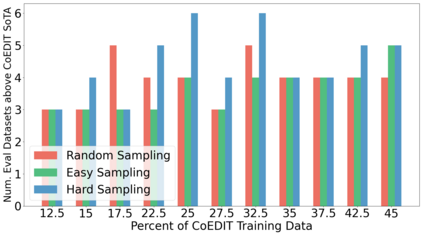
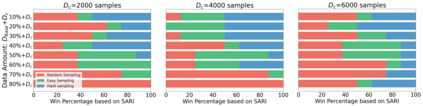
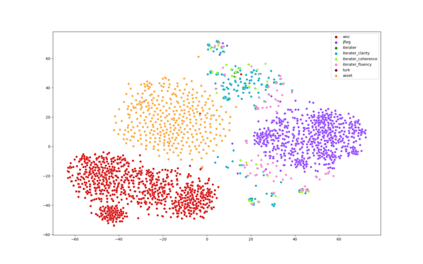
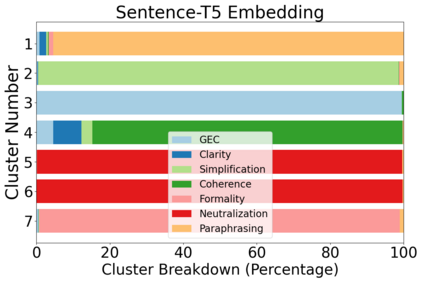
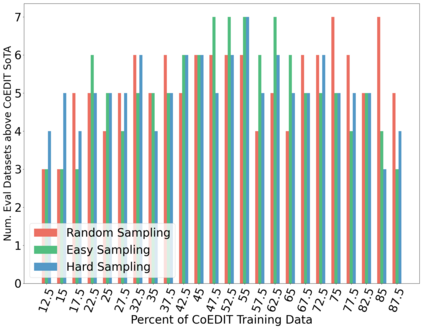
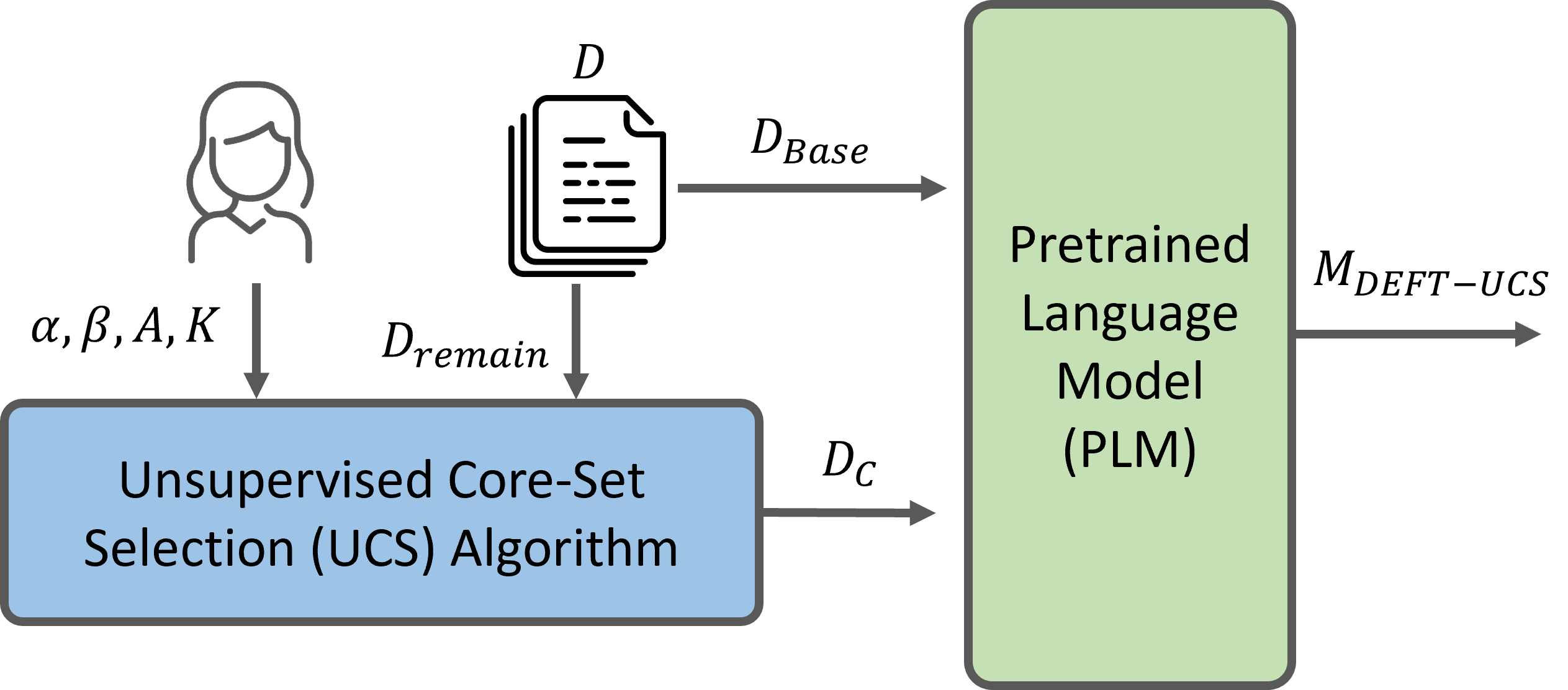
Recent advances have led to the availability of many pre-trained language models (PLMs); however, a question that remains is how much data is truly needed to fine-tune PLMs for downstream tasks? In this work, we introduce DEFT-UCS, a data-efficient fine-tuning framework that leverages unsupervised core-set selection to identify a smaller, representative dataset that reduces the amount of data needed to fine-tune PLMs for downstream tasks. We examine the efficacy of DEFT-UCS in the context of text-editing LMs, and compare to the state-of-the art text-editing model, CoEDIT. Our results demonstrate that DEFT-UCS models are just as accurate as CoEDIT, across eight different datasets consisting of six different editing tasks, while finetuned on 70% less data.
翻译:暂无翻译