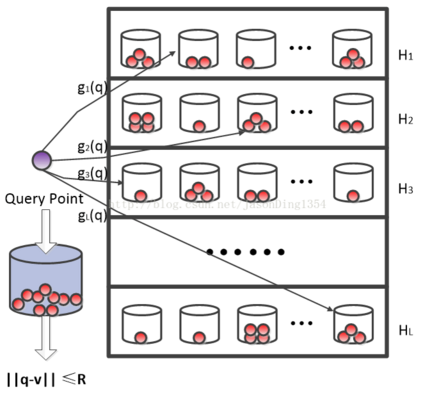
Hashing technology has been widely used in image retrieval due to its computational and storage efficiency. Recently, deep unsupervised hashing methods have attracted increasing attention due to the high cost of human annotations in the real world and the superiority of deep learning technology. However, most deep unsupervised hashing methods usually pre-compute a similarity matrix to model the pairwise relationship in the pre-trained feature space. Then this similarity matrix would be used to guide hash learning, in which most of the data pairs are treated equivalently. The above process is confronted with the following defects: 1) The pre-computed similarity matrix is inalterable and disconnected from the hash learning process, which cannot explore the underlying semantic information. 2) The informative data pairs may be buried by the large number of less-informative data pairs. To solve the aforementioned problems, we propose a Deep Self-Adaptive Hashing (DSAH) model to adaptively capture the semantic information with two special designs: Adaptive Neighbor Discovery (AND) and Pairwise Information Content (PIC). Firstly, we adopt the AND to initially construct a neighborhood-based similarity matrix, and then refine this initial similarity matrix with a novel update strategy to further investigate the semantic structure behind the learned representation. Secondly, we measure the priorities of data pairs with PIC and assign adaptive weights to them, which is relies on the assumption that more dissimilar data pairs contain more discriminative information for hash learning. Extensive experiments on several datasets demonstrate that the above two technologies facilitate the deep hashing model to achieve superior performance.
翻译:由于计算和储存效率的计算和储存效率,在图像检索中广泛使用了散列技术。最近,由于真实世界中人类笔记费用高昂,以及深层学习技术的优越性,深层未经监督的散列方法已引起越来越多的注意。然而,最深层未经监督的散列方法通常会预先计算出一个相似的矩阵,以模拟预先训练的特征空间中的对等关系。然后,这个相似的矩阵将用来指导散列学习,大多数数据配对在其中得到同等的处理。上述流程遇到了以下缺陷:(1) 预置的近似矩阵是无法变换的,与无法探索基本语义信息信息的学习过程脱节。 (2) 大部分较深层未经监督的散列方法通常会埋藏于大量较不易的数据配对配。 为了解决上述问题,我们建议用一个深层自我评估的散列模型(DSAH) 来适应性地获取精度信息。 上述方法遇到了以下两种特殊设计:(1) 适应性易变异性(AND) 和 Pairfrious信息矩阵是无法进行深度的, 初步的假设(PICtrial condeal condeal) rodustration redustration redustration redudestrutismation the the the the medududududududustration the slation),我们采用了了一种类似的数据结构。