【论文推荐】最新七篇图像检索相关论文—草图、Tie-Aware、场景图解析、叠加跨注意力机制、深度哈希、人群估计
【导读】专知内容组整理了最近七篇图像检索(Image Retrieval)相关文章,为大家进行介绍,欢迎查看!
1. Cross-Paced Representation Learning with Partial Curricula for Sketch-based Image Retrieval(基于草图的图像检索)
作者:Dan Xu,Xavier Alameda-Pineda,Jingkuan Song,Elisa Ricci,Nicu Sebe
机构:Indiana University
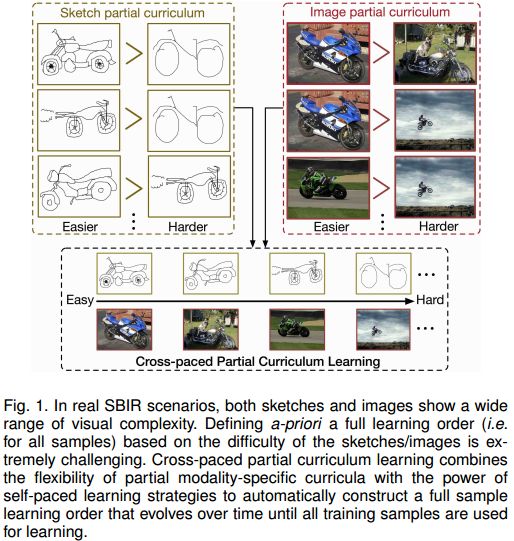
摘要:In this paper we address the problem of learning robust cross-domain representations for sketch-based image retrieval (SBIR). While most SBIR approaches focus on extracting low- and mid-level descriptors for direct feature matching, recent works have shown the benefit of learning coupled feature representations to describe data from two related sources. However, cross-domain representation learning methods are typically cast into non-convex minimization problems that are difficult to optimize, leading to unsatisfactory performance. Inspired by self-paced learning, a learning methodology designed to overcome convergence issues related to local optima by exploiting the samples in a meaningful order (i.e. easy to hard), we introduce the cross-paced partial curriculum learning (CPPCL) framework. Compared with existing self-paced learning methods which only consider a single modality and cannot deal with prior knowledge, CPPCL is specifically designed to assess the learning pace by jointly handling data from dual sources and modality-specific prior information provided in the form of partial curricula. Additionally, thanks to the learned dictionaries, we demonstrate that the proposed CPPCL embeds robust coupled representations for SBIR. Our approach is extensively evaluated on four publicly available datasets (i.e. CUFS, Flickr15K, QueenMary SBIR and TU-Berlin Extension datasets), showing superior performance over competing SBIR methods.
期刊:arXiv, 2018年3月5日
网址:
http://www.zhuanzhi.ai/document/2957bb1bb34af1c1cdf3cc61d72921a1
2. Hashing as Tie-Aware Learning to Rank
作者:Kun He,Fatih Cakir,Sarah Adel Bargal,Stan Sclaroff
机构:Boston University
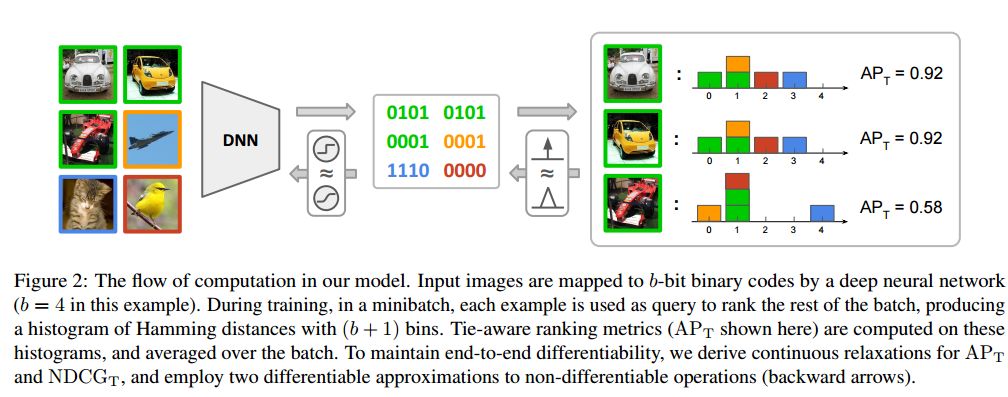
摘要:Hashing, or learning binary embeddings of data, is frequently used in nearest neighbor retrieval. In this paper, we develop learning to rank formulations for hashing, aimed at directly optimizing ranking-based evaluation metrics such as Average Precision (AP) and Normalized Discounted Cumulative Gain (NDCG). We first observe that the integer-valued Hamming distance often leads to tied rankings, and propose to use tie-aware versions of AP and NDCG to evaluate hashing for retrieval. Then, to optimize tie-aware ranking metrics, we derive their continuous relaxations, and perform gradient-based optimization with deep neural networks. Our results establish the new state-of-the-art for image retrieval by Hamming ranking in common benchmarks.
期刊:arXiv, 2018年3月2日
网址:
http://www.zhuanzhi.ai/document/f985750d27dc7820750606bc93d81cef
3. Scene Graph Parsing as Dependency Parsing(场景图解析)
作者:Yu-Siang Wang,Chenxi Liu,Xiaohui Zeng,Alan Yuille
机构:National Taiwan University
摘要:In this paper, we study the problem of parsing structured knowledge graphs from textual descriptions. In particular, we consider the scene graph representation that considers objects together with their attributes and relations: this representation has been proved useful across a variety of vision and language applications. We begin by introducing an alternative but equivalent edge-centric view of scene graphs that connect to dependency parses. Together with a careful redesign of label and action space, we combine the two-stage pipeline used in prior work (generic dependency parsing followed by simple post-processing) into one, enabling end-to-end training. The scene graphs generated by our learned neural dependency parser achieve an F-score similarity of 49.67% to ground truth graphs on our evaluation set, surpassing best previous approaches by 5%. We further demonstrate the effectiveness of our learned parser on image retrieval applications.

期刊:arXiv, 2018年3月25日
网址:
http://www.zhuanzhi.ai/document/3b343d6d496305a8329667a5429740bb
4. Stacked Cross Attention for Image-Text Matching(基于叠加跨注意力机制的图像文本匹配)
作者:Kuang-Huei Lee,Xi Chen,Gang Hua,Houdong Hu,Xiaodong He
摘要:In this paper, we study the problem of image-text matching. Inferring the latent semantic alignment between objects or other salient stuffs (e.g. snow, sky, lawn) and the corresponding words in sentences allows to capture fine-grained interplay between vision and language, and makes image-text matching more interpretable. Prior works either simply aggregate the similarity of all possible pairs of regions and words without attending differentially to more and less important words or regions, or use a multi-step attentional process to capture limited number of semantic alignments which is less interpretable. In this paper, we present Stacked Cross Attention to discover the full latent alignments using both image regions and words in sentence as context and infer the image-text similarity. Our approach achieves the state-of-the-art results on the MS-COCO and Flickr30K datasets. On Flickr30K, our approach outperforms the current best methods by 22.1% in text retrieval from image query, and 18.2% in image retrieval with text query (based on Recall@1). On MS-COCO, our approach improves sentence retrieval by 17.8% and image retrieval by 16.6% (based on Recall@1 using the 5K test set).

期刊:arXiv, 2018年3月22日
网址:
http://www.zhuanzhi.ai/document/e2dd0335c271dfc648e211dfdd5e6de8
5. Instance Similarity Deep Hashing for Multi-Label Image Retrieval(基于示例相似深度哈希的多标签图像检索)
作者:Zheng Zhang,Qin Zou,Qian Wang,Yuewei Lin,Qingquan Li
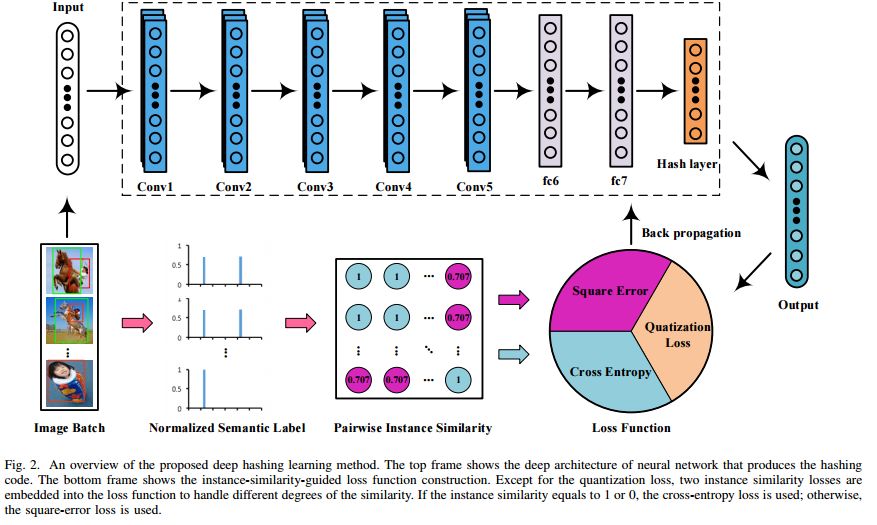
摘要:Hash coding has been widely used in the approximate nearest neighbor search for large-scale image retrieval. Recently, many deep hashing methods have been proposed and shown largely improved performance over traditional feature-learning-based methods. Most of these methods examine the pairwise similarity on the semantic-level labels, where the pairwise similarity is generally defined in a hard-assignment way. That is, the pairwise similarity is '1' if they share no less than one class label and '0' if they do not share any. However, such similarity definition cannot reflect the similarity ranking for pairwise images that hold multiple labels. In this paper, a new deep hashing method is proposed for multi-label image retrieval by re-defining the pairwise similarity into an instance similarity, where the instance similarity is quantified into a percentage based on the normalized semantic labels. Based on the instance similarity, a weighted cross-entropy loss and a minimum mean square error loss are tailored for loss-function construction, and are efficiently used for simultaneous feature learning and hash coding. Experiments on three popular datasets demonstrate that, the proposed method outperforms the competing methods and achieves the state-of-the-art performance in multi-label image retrieval.
期刊:arXiv, 2018年3月19日
网址:
http://www.zhuanzhi.ai/document/84f6aa6f3dc731f810f6d5431e8d2154
6. Leveraging Unlabeled Data for Crowd Counting by Learning to Rank(通过Learning to Rank机制利用未标记的数据进行人群估计)
作者:Xialei Liu,Joost van de Weijer,Andrew D. Bagdanov
机构:University of Florence
摘要:We propose a novel crowd counting approach that leverages abundantly available unlabeled crowd imagery in a learning-to-rank framework. To induce a ranking of cropped images , we use the observation that any sub-image of a crowded scene image is guaranteed to contain the same number or fewer persons than the super-image. This allows us to address the problem of limited size of existing datasets for crowd counting. We collect two crowd scene datasets from Google using keyword searches and query-by-example image retrieval, respectively. We demonstrate how to efficiently learn from these unlabeled datasets by incorporating learning-to-rank in a multi-task network which simultaneously ranks images and estimates crowd density maps. Experiments on two of the most challenging crowd counting datasets show that our approach obtains state-of-the-art results.

期刊:arXiv, 2018年3月8日
网址:
http://www.zhuanzhi.ai/document/959898f1e90353a9bc1222226c46a27e
7. Zero-Shot Sketch-Image Hashing(基于Zero-Shot草图图像哈希)
作者:Yuming Shen,Li Liu,Fumin Shen,Ling Shao
机构:University of East Anglia
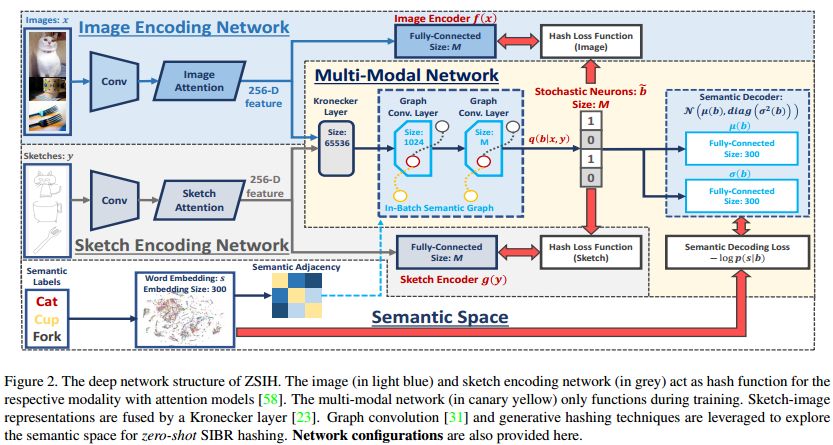
摘要:Recent studies show that large-scale sketch-based image retrieval (SBIR) can be efficiently tackled by cross-modal binary representation learning methods, where Hamming distance matching significantly speeds up the process of similarity search. Providing training and test data subjected to a fixed set of pre-defined categories, the cutting-edge SBIR and cross-modal hashing works obtain acceptable retrieval performance. However, most of the existing methods fail when the categories of query sketches have never been seen during training. In this paper, the above problem is briefed as a novel but realistic zero-shot SBIR hashing task. We elaborate the challenges of this special task and accordingly propose a zero-shot sketch-image hashing (ZSIH) model. An end-to-end three-network architecture is built, two of which are treated as the binary encoders. The third network mitigates the sketch-image heterogeneity and enhances the semantic relations among data by utilizing the Kronecker fusion layer and graph convolution, respectively. As an important part of ZSIH, we formulate a generative hashing scheme in reconstructing semantic knowledge representations for zero-shot retrieval. To the best of our knowledge, ZSIH is the first zero-shot hashing work suitable for SBIR and cross-modal search. Comprehensive experiments are conducted on two extended datasets, i.e., Sketchy and TU-Berlin with a novel zero-shot train-test split. The proposed model remarkably outperforms related works.
期刊:arXiv, 2018年3月7日
网址:
http://www.zhuanzhi.ai/document/b75b91c696ff3fd5288d864964ce4061
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
投稿&广告&商务合作:fangquanyi@gmail.com
点击“阅读原文”,使用专知



