【论文推荐】最新五篇图像分割相关论文—R2U-Net、ScatterNet混合深度学习、分离卷积编解码、控制、Embedding
【导读】专知内容组整理了最近五篇图像分割(Image Segmentation)相关文章,为大家进行介绍,欢迎查看!
1. Recurrent Residual Convolutional Neural Network based on U-Net (R2U-Net) for Medical Image Segmentation(基于U-Net (R2U-Net)循环残差卷积神经网络的医学图像分割)
作者:Md Zahangir Alom,Mahmudul Hasan,Chris Yakopcic,Tarek M. Taha,Vijayan K. Asari
摘要:Deep learning (DL) based semantic segmentation methods have been providing state-of-the-art performance in the last few years. More specifically, these techniques have been successfully applied to medical image classification, segmentation, and detection tasks. One deep learning technique, U-Net, has become one of the most popular for these applications. In this paper, we propose a Recurrent Convolutional Neural Network (RCNN) based on U-Net as well as a Recurrent Residual Convolutional Neural Network (RRCNN) based on U-Net models, which are named RU-Net and R2U-Net respectively. The proposed models utilize the power of U-Net, Residual Network, as well as RCNN. There are several advantages of these proposed architectures for segmentation tasks. First, a residual unit helps when training deep architecture. Second, feature accumulation with recurrent residual convolutional layers ensures better feature representation for segmentation tasks. Third, it allows us to design better U-Net architecture with same number of network parameters with better performance for medical image segmentation. The proposed models are tested on three benchmark datasets such as blood vessel segmentation in retina images, skin cancer segmentation, and lung lesion segmentation. The experimental results show superior performance on segmentation tasks compared to equivalent models including U-Net and residual U-Net (ResU-Net).
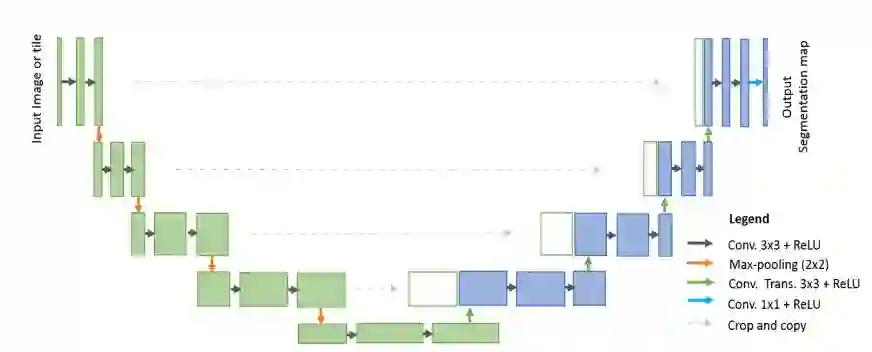
期刊:arXiv, 2018年2月20日
网址:
http://www.zhuanzhi.ai/document/c08f73b6bbc5c5d5cf9c3ca159e1003e
2. Generative ScatterNet Hybrid Deep Learning (G-SHDL) Network with Structural Priors for Semantic Image Segmentation(结合结构先验的产生式ScatterNet混合深度学习(G-SHDL)网络的语义图像分割)
作者:Amarjot Singh,Nick Kingsbury
摘要:This paper proposes a generative ScatterNet hybrid deep learning (G-SHDL) network for semantic image segmentation. The proposed generative architecture is able to train rapidly from relatively small labeled datasets using the introduced structural priors. In addition, the number of filters in each layer of the architecture is optimized resulting in a computationally efficient architecture. The G-SHDL network produces state-of-the-art classification performance against unsupervised and semi-supervised learning on two image datasets. Advantages of the G-SHDL network over supervised methods are demonstrated with experiments performed on training datasets of reduced size.

期刊:arXiv, 2018年2月13日
网址:
http://www.zhuanzhi.ai/document/1c39cdbddc9b6f56ca2246ca394109ef
3. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation(可分离卷积编解码的语义图像分割)
作者:Liang-Chieh Chen,Yukun Zhu,George Papandreou,Florian Schroff,Hartwig Adam
摘要:Spatial pyramid pooling module or encode-decoder structure are used in deep neural networks for semantic segmentation task. The former networks are able to encode multi-scale contextual information by probing the incoming features with filters or pooling operations at multiple rates and multiple effective fields-of-view, while the latter networks can capture sharper object boundaries by gradually recovering the spatial information. In this work, we propose to combine the advantages from both methods. Specifically, our proposed model, DeepLabv3+, extends DeepLabv3 by adding a simple yet effective decoder module to refine the segmentation results especially along object boundaries. We further explore the Xception model and apply the depthwise separable convolution to both Atrous Spatial Pyramid Pooling and decoder modules, resulting in a faster and stronger encoder-decoder network. We demonstrate the effectiveness of the proposed model on the PASCAL VOC 2012 semantic image segmentation dataset and achieve a performance of 89% on the test set without any post-processing. Our paper is accompanied with a publicly available reference implementation of the proposed models in Tensorflow.
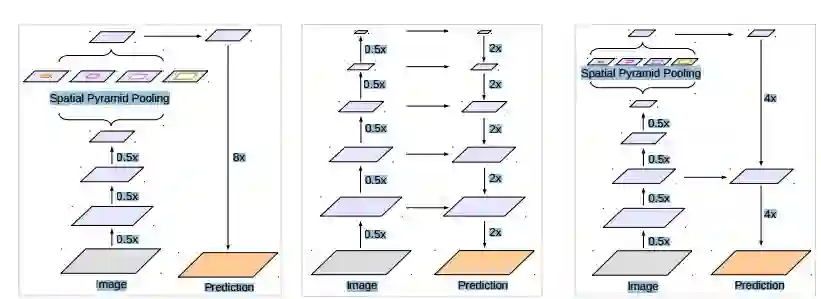
期刊:arXiv, 2018年2月8日
网址:
http://www.zhuanzhi.ai/document/184bb9965aeaf1e3670ffd9bbd1eafd7
4. Virtual-to-Real: Learning to Control in Visual Semantic Segmentation(Virtual-to-Real:视觉语义分割的控制学习)
作者:Zhang-Wei Hong,Chen Yu-Ming,Shih-Yang Su,Tzu-Yun Shann,Yi-Hsiang Chang,Hsuan-Kung Yang,Brian Hsi-Lin Ho,Chih-Chieh Tu,Yueh-Chuan Chang,Tsu-Ching Hsiao,Hsin-Wei Hsiao,Sih-Pin Lai,Chun-Yi Lee
摘要:Collecting training data from the physical world is usually time-consuming and even dangerous for fragile robots, and thus, recent advances in robot learning advocate the use of simulators as the training platform. Unfortunately, the reality gap between synthetic and real visual data prohibits direct migration of the models trained in virtual worlds to the real world. This paper proposes a modular architecture for tackling the virtual-to-real problem. The proposed architecture separates the learning model into a perception module and a control policy module, and uses semantic image segmentation as the meta representation for relating these two modules. The perception module translates the perceived RGB image to semantic image segmentation. The control policy module is implemented as a deep reinforcement learning agent, which performs actions based on the translated image segmentation. Our architecture is evaluated in an obstacle avoidance task and a target following task. Experimental results show that our architecture significantly outperforms all of the baseline methods in both virtual and real environments, and demonstrates a faster learning curve than them. We also present a detailed analysis for a variety of variant configurations, and validate the transferability of our modular architecture.
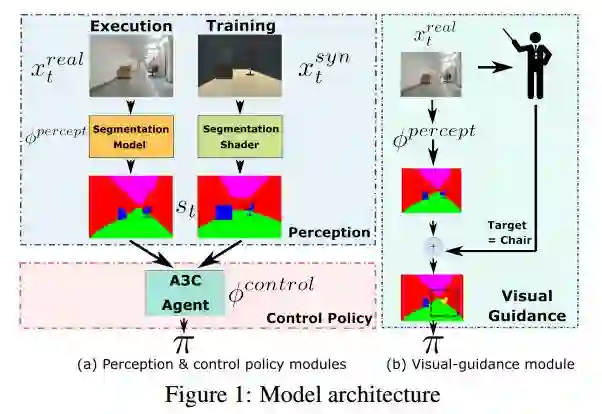
期刊:arXiv, 2018年2月1日
网址:
http://www.zhuanzhi.ai/document/605990428897bce5c667510d9a836a74
5. Piecewise Flat Embedding for Image Segmentation
作者:Chaowei Fang, Zicheng Liao, Yizhou Yu
摘要:We propose a new nonlinear embedding -- Piecewise Flat Embedding (PFE) -- for image segmentation. Based on the theory of sparse signal recovery, piecewise flat embedding attempts to recover a piecewise constant image representation with sparse region boundaries and sparse cluster value scattering. The resultant piecewise flat embedding exhibits interesting properties such as suppressing slowly varying signals, and offers an image representation with higher region identifiability which is desirable for image segmentation or high-level semantic analysis tasks. We formulate our embedding as a variant of the Laplacian Eigenmap embedding with an L1,p(0<p≤1) regularization term to promote sparse solutions. First, we devise a two-stage numerical algorithm based on Bregman iterations to compute L1,1-regularized piecewise flat embeddings. We further generalize this algorithm through iterative reweighting to solve the general L1,p-regularized problem. To demonstrate its efficacy, we integrate PFE into two existing image segmentation frameworks, segmentation based on clustering and hierarchical segmentation based on contour detection. Experiments on four major benchmark datasets, BSDS500, MSRC, Stanford Background Dataset, and PASCAL Context, show that segmentation algorithms incorporating our embedding achieve significantly improved results.

期刊:arXiv, 2018年2月9日
网址:
https://arxiv.org/abs/1802.03248v2
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!




