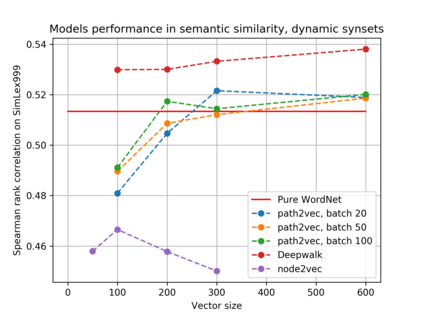
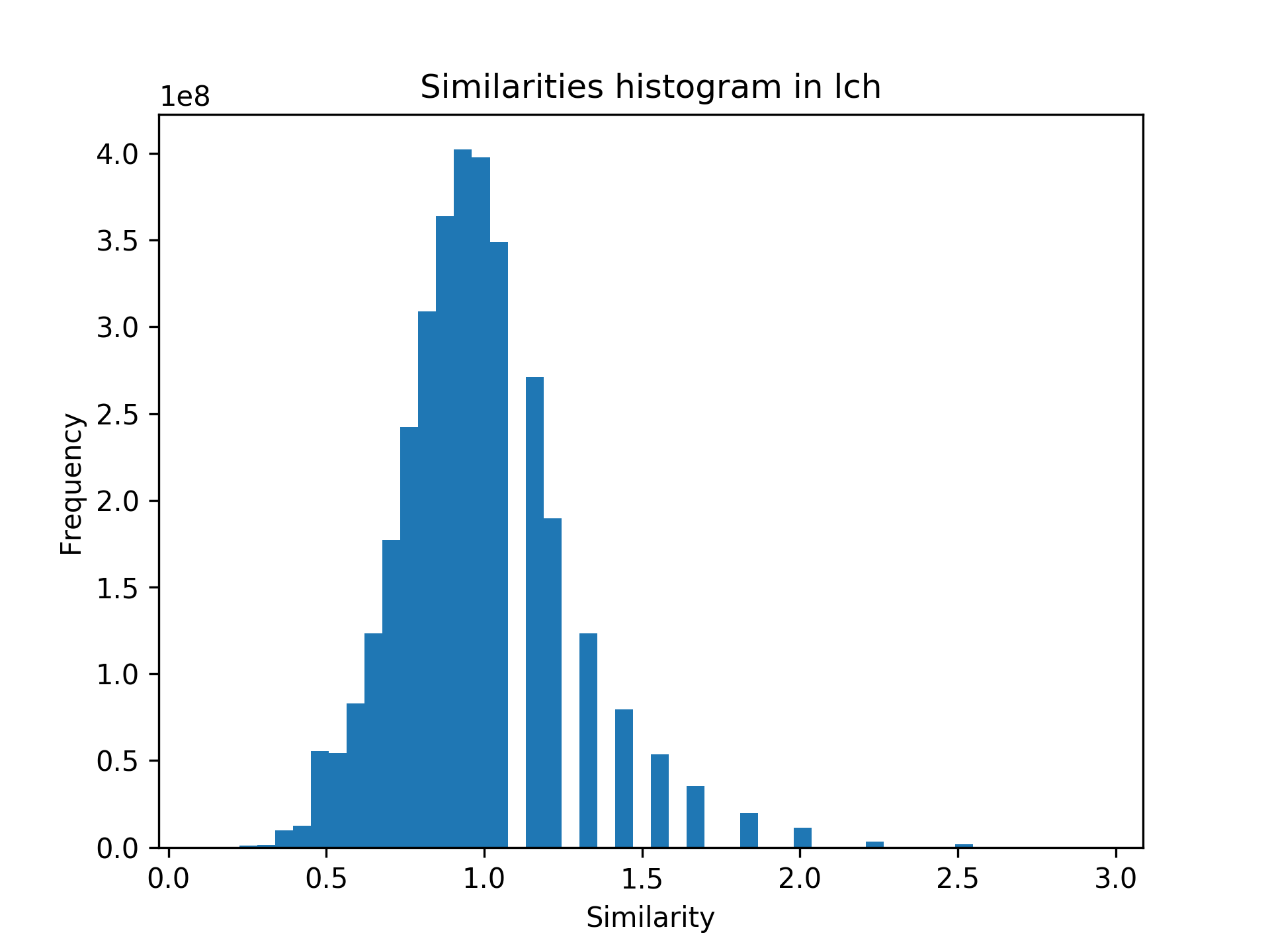
We present a new approach for learning graph embeddings, that relies on structural measures of node similarities for generation of training data. The model learns node embeddings that are able to approximate a given measure, such as the shortest path distance or any other. Evaluations of the proposed model on semantic similarity and word sense disambiguation tasks (using WordNet as the source of gold similarities) show that our method yields state-of-the-art results, but also is capable in certain cases to yield even better performance than the input similarity measure. The model is computationally efficient, orders of magnitude faster than the direct computation of graph distances.
翻译:我们提出了一个学习图表嵌入的新方法,它依赖于生成培训数据时节点相似的结构性测量方法。模型学习能够接近某一计量的节点嵌入方法,例如最短的路径距离或其他任何方法。对语义相似性和字义感模糊化任务的拟议模型(使用WordNet作为黄金相似之处的来源)的评估表明,我们的方法产生最新的结果,但在某些情况下,也能够产生比输入相似度测量更好的性能。模型的计算效率比直接计算图形距离的速度快,数量级比直接计算数字距离快。