自然语言处理 (三) 之 word embedding
自然语言处理 之 word embedding
理解每个word的意思是自然语言处理的一大核心,那么怎样才能很好的描述word与word之间的syntactic & semantic similarity呢? 这里介绍几种主流的word embedding 方法,即把word 映射到维度为d的向量,然后用向量间的cosine 距离或内积描述word与word间的句法和语义相似度。
大家一定知道word2vec, 它发表于2013年,由于其在 word analogy, word similarity ...多个linguistic tasks上面的excellent performance,而且它比其余大部分neural network embedding 方法 (如NNLM,RNN, LSTM)training时更加的efficient, 使得它名噪一时。word2vec 最后可以得到一些有趣的Linear regularities, 比如 Beijing – China + France ~= Paris。那么 word2vec 以及后来的 Glove, 相比其它的embedding模型 (如LSA), 是否真的有模型上无比的优越性呢?答案是否定的。首先我们来介绍word embedding 模型。
1. LSA: Latent semantic indexing
Singular value decomposition (SVD),也就是大家熟知的 latent semantic index (LSI), 它成功的应用于word embedding,基本思想既优美又直观: 给定 word-document 矩阵 Mmxn, 每一行代表一个word, 每一列代表一个document, M中每个entry M(i,j) 代表第i个word在第j个document中出现的频率,如果我们用SVD 把矩阵M 分解成: M = UDVT, 每个矩阵UDV的秩为k,其中 k<<m, k<<n, 那么我们就可以使用 W = UD 中的每一行(k维)来作为每个word的embedding vector,W就称为 word embedding matrix。可以很容易的证明:M*MT = W*WT, 那么为什么不使用M中的每一行当作embed words 呢? 原因有两个:首先,M中的每一行都是一个高维的向量,务必会带来更多的计算量; 其次,一个高维的向量的generalizability, 往往不如低维向量 (arguable)。
那么为什么SVD得到的 embedding vectors能描述word与word间的semantic similarity呢?首先我们强调下: LSI 能(部分)解决synonym (同义词) 问题, 而不能解决polysemy问题。那么它怎样解决同义词问题的呢? 比如 car 和 automobile, 为什么它们间的embedding vector具有较大的相似度? 原因是: 如果 car 和 automobile总是会同时出现在同一个document中,那么它们见的相似度很大 (即 car 和 automobile 在 word-document 矩阵中对应的行向量间的correlation 很大,接近1); 如果我们考虑下面这种情况:automobile 和 car从来不会同时出现在同一document中, 那么SVD得到的embedding, 它们还有相似度吗? 没有, 因为M矩阵中,automobile 的向量与car的向量是perpendicular的,内积为0, cosine 也为0,因此得到的W矩阵中, automobile 和 car 的embedding vector 同样是垂直的; 好了, 我们考虑最真实的情形:有些document中只有car, 有些只有 automobile, 而有些同时出现 car & automobile, 这种情况下,M矩阵中automobile 的向量与car的向量就会有affinity,所以embedding后的向量也会相似。
后记:1999年,Thomas Hofmann 提出了 probabilistic latent semantic indexing (pLSI), 把M矩阵(word-document矩阵)分解用概率图模型来描述, 即 p(d,w) = Σp(w|t)p(t|d)p(d), 其中t代表了 latent topics。不过值得注意的:通过maximum likelihood estimation (MLE), 得到了每个topic 下word的distribution p(w|t) 和每个document中topic的distribution p(t|d), 并没有得到每个word的一个vector embedding。pLSI最大的弱点是: 对于一个新的document, 要想得到它的topic distribution p(t|d), 必须要再做一次inference, 使得pLSI的算法复杂度很高。
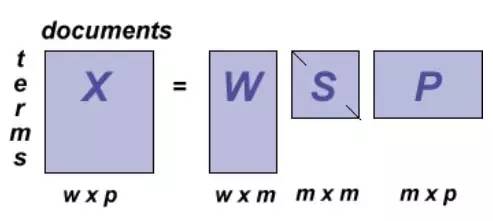
2. Pointwise mutual information (PMI)
LSI的input是一个word-document 频率矩阵,PMI的input是一个word-context矩阵。那么document 和 context的区别和联系在哪里呢? 其实 document 是一种context, 所以PMI的input理论上也可以是 word-document。最常用的context是 L个连续的words (大家可以想象 skip-gram中的context, 它们是一样的概念)。那么PMI用信息论中的mutual information来描述每个word 和 每个context间的association, 即: PMI(w,c) = log{p(w,c)/[p(w)p(c)]}, 其中p(w,c),p(w) 和 p(c) 分别表示特定的 word-context pair, word, context 在 所有的 word-context pairs 中出现的频率。
给定了一个PMI矩阵,每行就是一个word的embedding, 两个word间的相似度, 就可以通过他们embedding vector 的cosine或内积来算出。
可以知道: PMI 中每个word的vector embedding同样是个非常高维的向量, 因为往往context的个数非常多,而且还是dense的 (word-document矩阵中每个word的embedding vector 是sparse的,因为每个word并不是在每个document中都会出现),不仅如此,它还是ill-defined, 因为会有 -∞出现。那么实际中怎么使用PMI矩阵呢? 实际中, 我们使用 PPMI metric来描述 word-context见的association, 即 PPMI(w,c) = max(PMI(w,c), 0), PPMI embedded vector 在实际中能较好的描述word间的相似度。
后记: 使用PPMI 的行向量来描述word, 同样是个高维的embedding vector, 我们可以把PPMI当作LSI的input, 使用SVD来得到word的K维空间中的embedding。
3. skip-gram
Skip-gram 在2013年由 Mikolov, Sutskever and Chen 提出,用于找到word embeddings that are useful for predicting surrounding words。skip-gram的目标函数是 最大化log probabilities, 最后可以得到每个word的embedding。2014 年, levy & Goldberg 证明了skip-gram word embedding模型等价于分解 shifted positive PMI word-context 矩阵,即: shifted PPMI = W*C, 其中W矩阵的每行就是每个word的embedded vector。
我们上面提到: SVD 也可以对PPMI矩阵分解,即: PPMI = UDV’,其中 W = UD矩阵的每一行是一个word的embedding vector。既然, skip-gram 和 SVD 都是对同一个矩阵分解,那么 为什么一般情况下, skip-gram 在 word analogy, word similarities 等等tasks上的performance 会好于 SVD呢? skip-gram分解的过程是symmetric的,即: W,C 都是任意矩阵, 它们不正交,而SVD得到的U,V矩阵是正交的,而且SVD得到的word embedding 是 UD, context embedding 是v, 这也是一种non-symmetric 的表征; 还有很多原因影响到了skip-gram 和 SVD在实际中不同的performance, 比如 context distribution smoothing, dynamic context window 等等, 具体参照 Levy et al. 2015的文章: Improving distributional similarity with lessons learned from word embeddings.
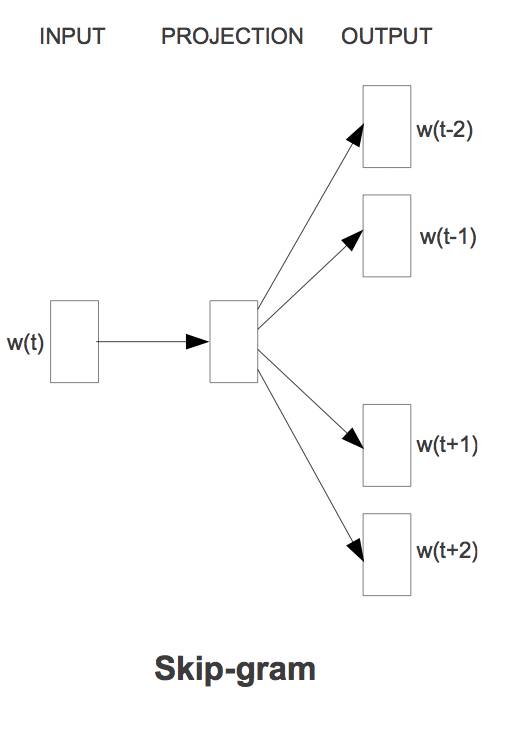
我们这里描述了3中常见的、流行的word embedding 方法, 其中PPMI是直接用 word-context 矩阵的每行 描述每个word的embedding, 而 LSI (SVD) 和 skip-gram是对PPMI矩阵的分解,然后用低维空间中的向量来描述每个word。这三者的关系犹豫:用原始的向量描述每个点,还是用PCA降维后的低维向量来描述每个点。总之,PPMI,LSI & skip-gram是基于相同的input 矩阵的,不同的是它们的优化方法。那么我们可想而知,一种embedding 方式会明显好于其它的吗?其余的吗? 答案是否定的,之所以skip-gram一般情况下会有好与其余方式的结果, 正是因为skip-gram优化过程中用了很多hyper-parameters, 它的好的performance不用来自模型本身(因为它实质也是矩阵分解),而是hyper-parameter tuning的结果。具体参照 Levy et al. 2015的文章: Improving distributional similarity with lessons learned from word embeddings.
DeepLearning中文论坛公众号的原创文章,欢迎转发;如需转载,请注明出处。谢谢!
掌握更多 Deep Learning 技术与资讯,请搜索微信号deeplearningforum或扫描以下二维码。
长按以下二维码,关注该公众号




