
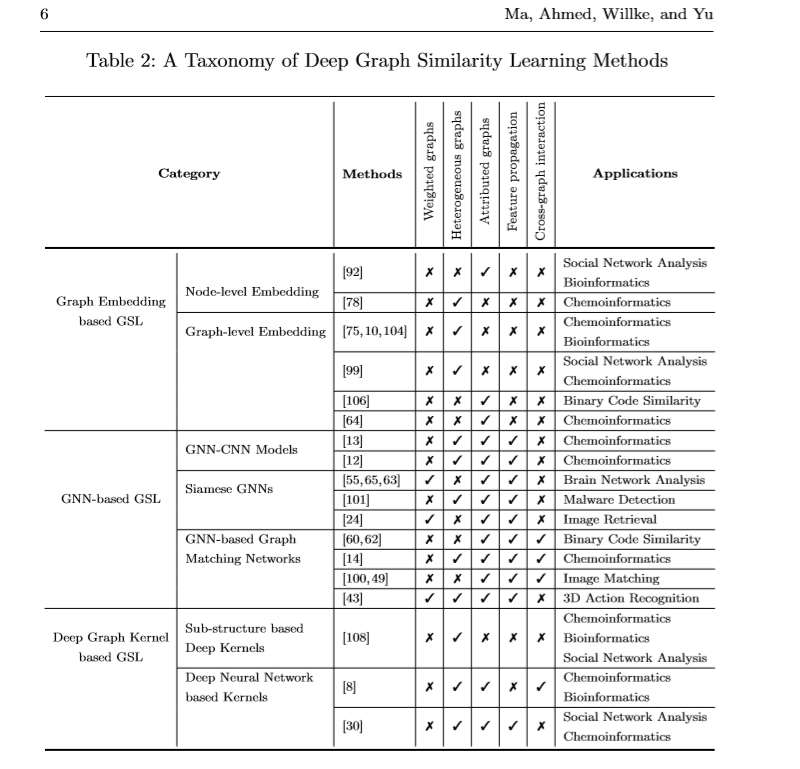
简介: 在许多将数据表示为图形的领域中,学习图形之间的相似性度量标准被认为是一个关键问题,它可以进一步促进各种学习任务,例如分类,聚类和相似性搜索。 最近,人们对深度图相似性学习越来越感兴趣,其中的主要思想是学习一种深度学习模型,该模型将输入图映射到目标空间,以使目标空间中的距离近似于输入空间中的结构距离。 在这里,我们提供对深度图相似性学习的现有文献的全面回顾。 我们为方法和应用提出了系统的分类法。 最后,我们讨论该问题的挑战和未来方向。
在特征空间上学习足够的相似性度量可以显着确定机器学习方法的性能。从数据自动学习此类度量是相似性学习的主要目的。相似度/度量学习是指学习一种功能以测量对象之间的距离或相似度,这是许多机器学习问题(例如分类,聚类,排名等)中的关键步骤。例如,在k最近邻(kNN)中分类[25],需要一个度量来测量数据点之间的距离并识别最近的邻居;在许多聚类算法中,数据点之间的相似性度量用于确定聚类。尽管有一些通用度量标准(例如欧几里得距离)可用于获取表示为矢量的对象之间的相似性度量,但是这些度量标准通常无法捕获正在研究的数据的特定特征,尤其是对于结构化数据。因此,找到或学习一种度量以测量特定任务中涉及的数据点的相似性至关重要。
成为VIP会员查看完整内容

相关内容

专知会员服务
159+阅读 · 2020年4月2日
专知会员服务
60+阅读 · 2019年11月16日
专知会员服务
93+阅读 · 2019年11月15日
Arxiv
6+阅读 · 2018年3月28日




相关VIP内容
专知会员服务
159+阅读 · 2020年4月2日
专知会员服务
60+阅读 · 2019年11月16日
专知会员服务
93+阅读 · 2019年11月15日
相关资讯
相关论文
Arxiv
6+阅读 · 2018年3月28日