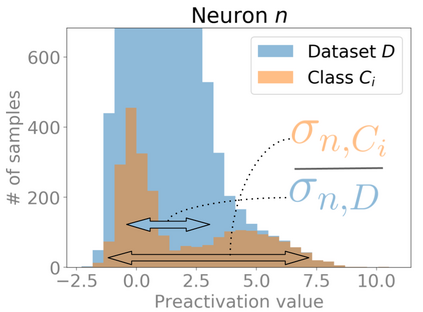
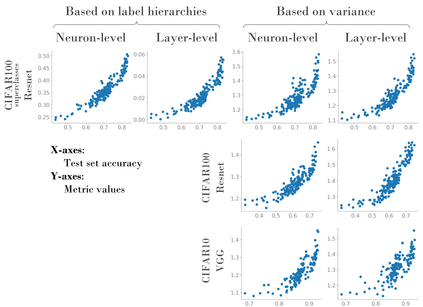
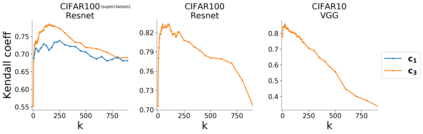
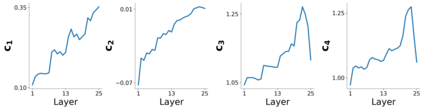
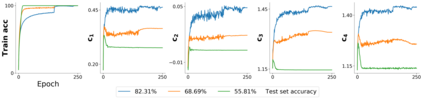
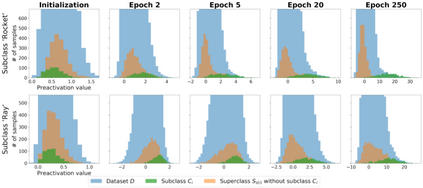
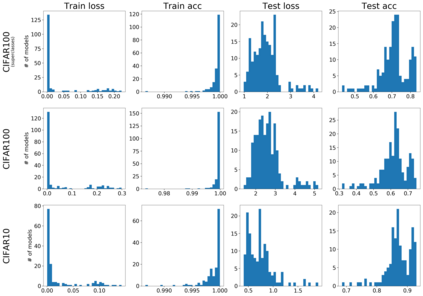
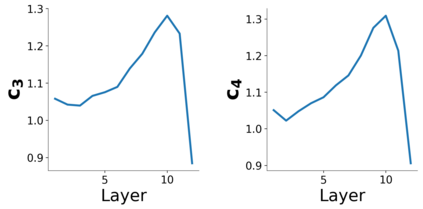
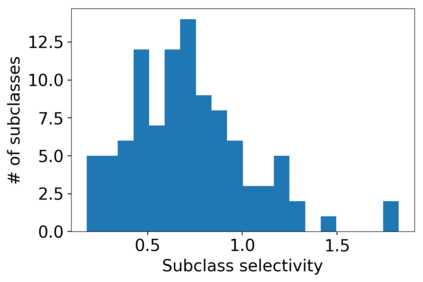
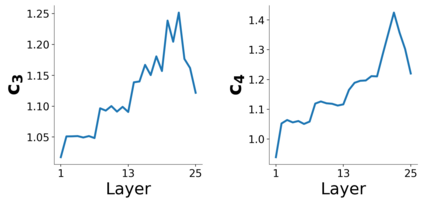
Several works have shown that the regularization mechanisms underlying deep neural networks' generalization performances are still poorly understood. In this paper, we hypothesize that deep neural networks are regularized through their ability to extract meaningful clusters among the samples of a class. This constitutes an implicit form of regularization, as no explicit training mechanisms or supervision target such behaviour. To support our hypothesis, we design four different measures of intraclass clustering, based on the neuron- and layer-level representations of the training data. We then show that these measures constitute accurate predictors of generalization performance across variations of a large set of hyperparameters (learning rate, batch size, optimizer, weight decay, dropout rate, data augmentation, network depth and width).
翻译:一些工作表明,深神经网络一般化绩效所依据的正规化机制仍然不甚为人知,在本文中,我们假设深神经网络通过在某一类样本中提取有意义的集群的能力而正规化,这构成了一种隐含的正规化形式,因为没有明确的培训机制或监督针对这种行为。为了支持我们的假设,我们根据培训数据的神经元和层级表示,设计了四种不同类别内部集群的计量方法。然后,我们表明,这些措施构成了一套大型超参数(学习率、批量大小、优化、体重衰减、辍学率、数据扩增、网络深度和宽度)各种变化的总体化绩效的准确预测。