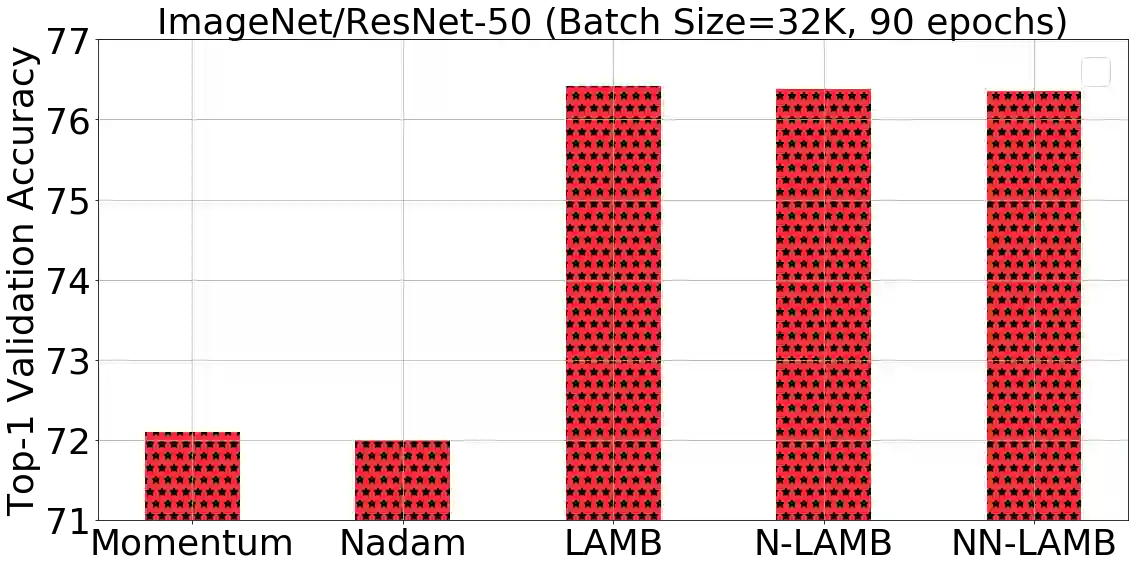
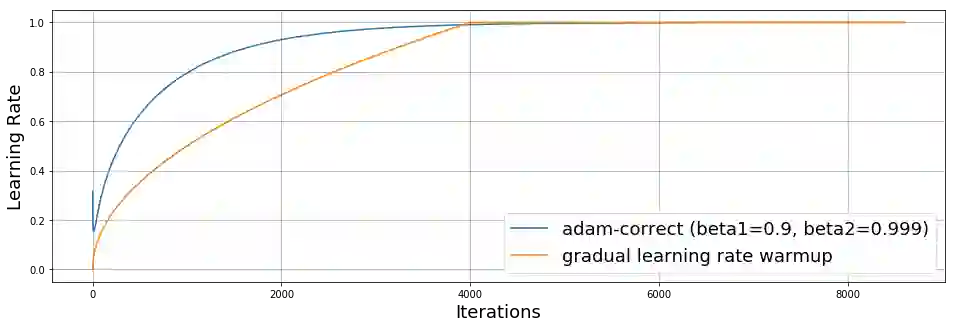
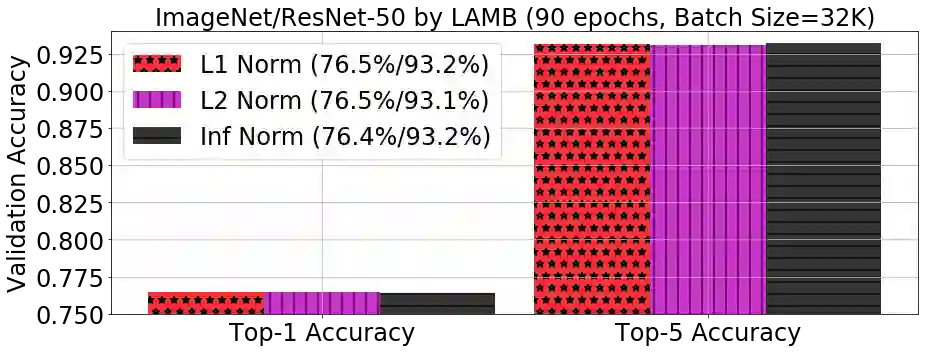
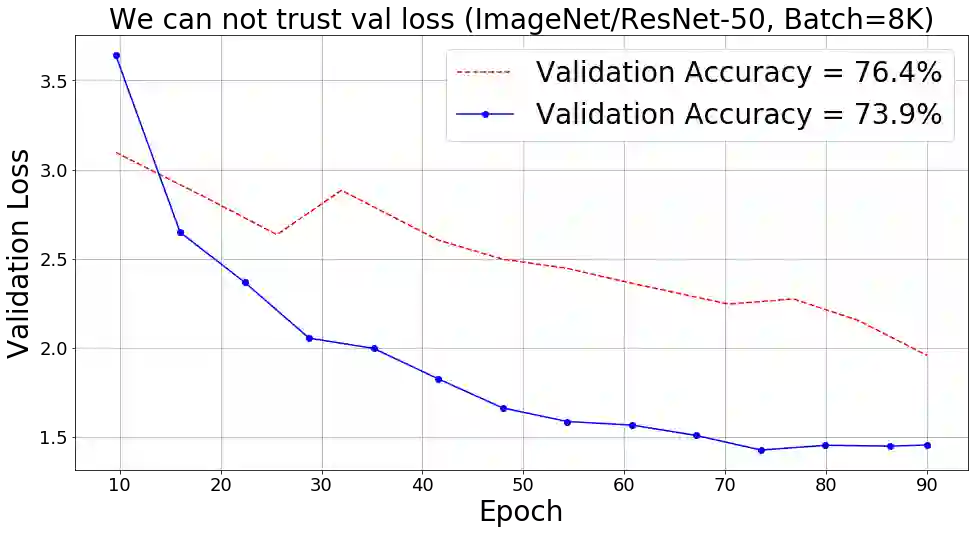
Training large deep neural networks on massive datasets is computationally very challenging. There has been recent surge in interest in using large batch stochastic optimization methods to tackle this issue. The most prominent algorithm in this line of research is LARS, which by employing layerwise adaptive learning rates trains ResNet on ImageNet in a few minutes. However, LARS performs poorly for attention models like BERT, indicating that its performance gains are not consistent across tasks. In this paper, we first study a principled layerwise adaptation strategy to accelerate training of deep neural networks using large mini-batches. Using this strategy, we develop a new layerwise adaptive large batch optimization technique called LAMB; we then provide convergence analysis of LAMB as well as LARS, showing convergence to a stationary point in general nonconvex settings. Our empirical results demonstrate the superior performance of LAMB across various tasks such as BERT and ResNet-50 training with very little hyperparameter tuning. In particular, for BERT training, our optimizer enables use of very large batch sizes of 32868 without any degradation of performance. By increasing the batch size to the memory limit of a TPUv3 Pod, BERT training time can be reduced from 3 days to just 76 minutes (Table 1).
翻译:对大型数据集的大型深心神经网络的培训在计算上具有巨大的挑战性。最近人们对使用大型批量随机优化方法来解决这一问题的兴趣激增。这一研究领域最突出的算法是LARS, 使用分层适应性学习率在几分钟内将ResNet在图像网络上培训ResNet。然而,LARS在像BERT这样的关注模型方面表现不佳, 表明其绩效收益在任务之间并不一致。 在本文件中, 我们首先研究一个有原则的层次性适应性适应战略, 以加快使用大型微型小孔对深神经网络的培训。 我们利用这一战略开发了一个新的层次适应性适应性适应性大型批量优化技术, 名为LAMB; 我们随后对LAMB以及LARS进行趋同分析, 显示在一般非convex环境中与固定点的趋同。 我们的经验结果表明, LAMBBB在诸如BERT和ResNet-50培训等各种任务中表现优异性。 特别是, 我们的优化性能使非常大型的3686批次规模能够使用, 而不会降解性性地使用。通过将批量培训时间范围从76 PPU3号压缩至1号。