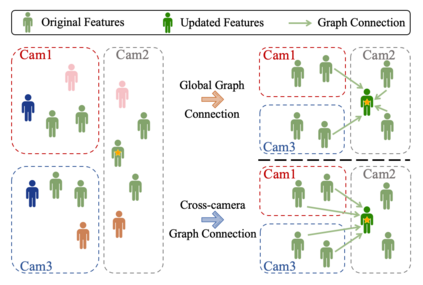
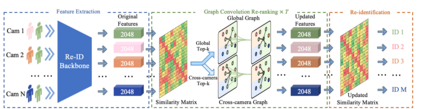
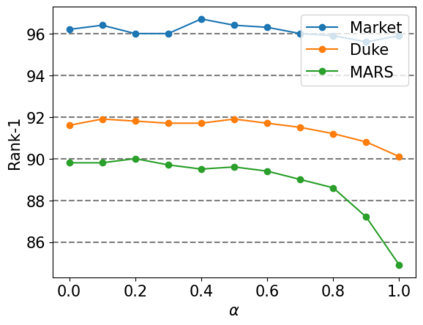
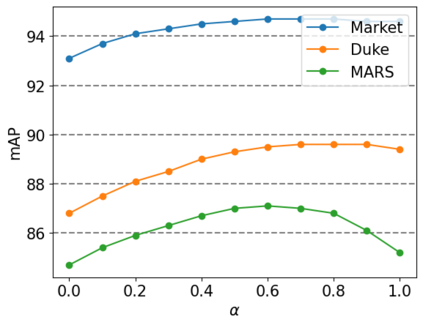
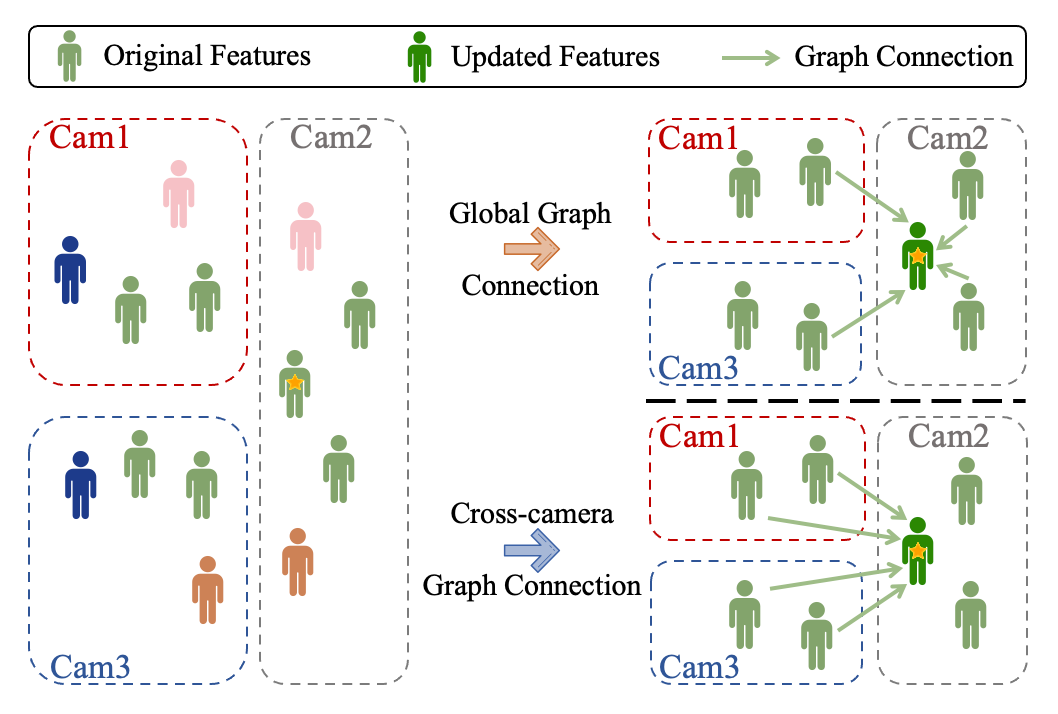
Nowadays, deep learning is widely applied to extract features for similarity computation in person re-identification (re-ID) and have achieved great success. However, due to the non-overlapping between training and testing IDs, the difference between the data used for model training and the testing data makes the performance of learned feature degraded during testing. Hence, re-ranking is proposed to mitigate this issue and various algorithms have been developed. However, most of existing re-ranking methods focus on replacing the Euclidean distance with sophisticated distance metrics, which are not friendly to downstream tasks and hard to be used for fast retrieval of massive data in real applications. In this work, we propose a graph-based re-ranking method to improve learned features while still keeping Euclidean distance as the similarity metric. Inspired by graph convolution networks, we develop an operator to propagate features over an appropriate graph. Since graph is the essential key for the propagation, two important criteria are considered for designing the graph, and three different graphs are explored accordingly. Furthermore, a simple yet effective method is proposed to generate a profile vector for each tracklet in videos, which helps extend our method to video re-ID. Extensive experiments on three benchmark data sets, e.g., Market-1501, Duke, and MARS, demonstrate the effectiveness of our proposed approach.
翻译:目前,深层次的学习被广泛用于提取个人再识别(再识别)的相似性计算特征,并取得了巨大成功,然而,由于培训和测试ID之间没有重叠,模型培训使用的数据与测试数据之间的差异使得测试过程中学习特征的性能退化,因此建议重新排序以缓解这一问题,并开发了各种算法,但是,大多数现有的重新排序方法侧重于用复杂的距离度量标准取代欧几里德距离,这些标准对下游任务不友好,难以用于快速检索真实应用中的大规模数据。在这项工作中,我们提出了一种基于图表的重新排序方法,以改进学习特征,同时保持欧几里德纳的距离作为相似度度度度度指标。在图相变网络的启发下,我们开发了一名操作员,在适当的图表上传播特征。由于图表是关键的,因此考虑了设计图表的两个重要标准,并相应地探讨了三个不同的图表。此外,我们提出了一种简单而有效的方法,为每个轨道的电子应用程序生成一个剖面矢量矢量矢量矢量,有助于将我们的方法扩大到三个视频基点、MAR01和MARIS数据库。