
题目: Cross-Modality Attention with Semantic Graph Embedding for Multi-Label Classification
简介:
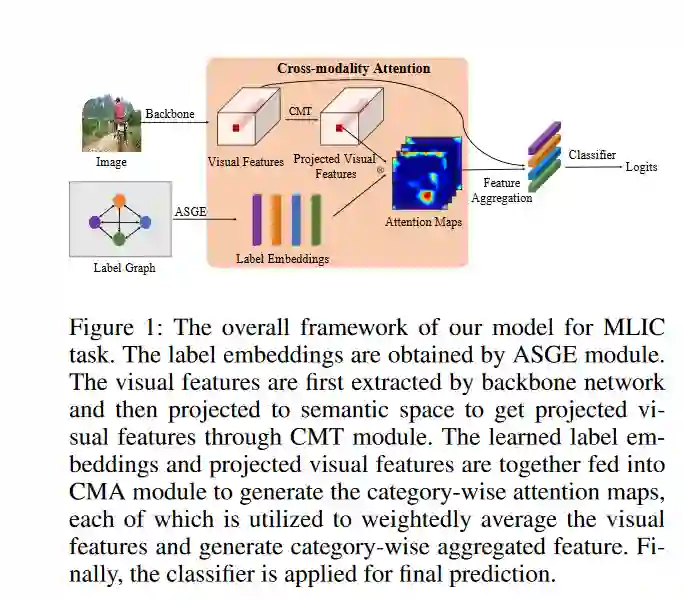
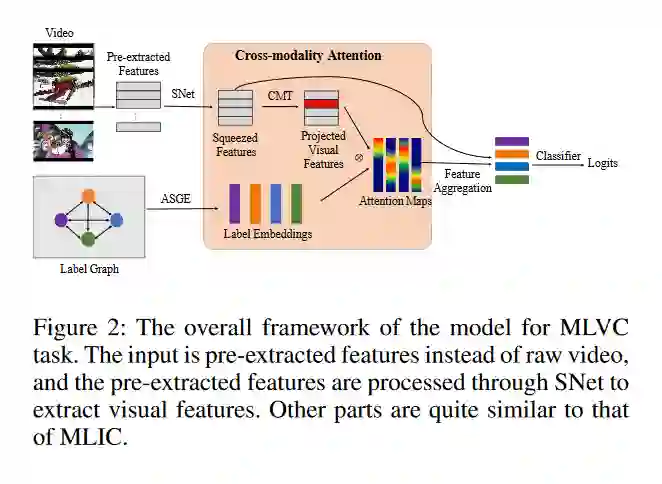
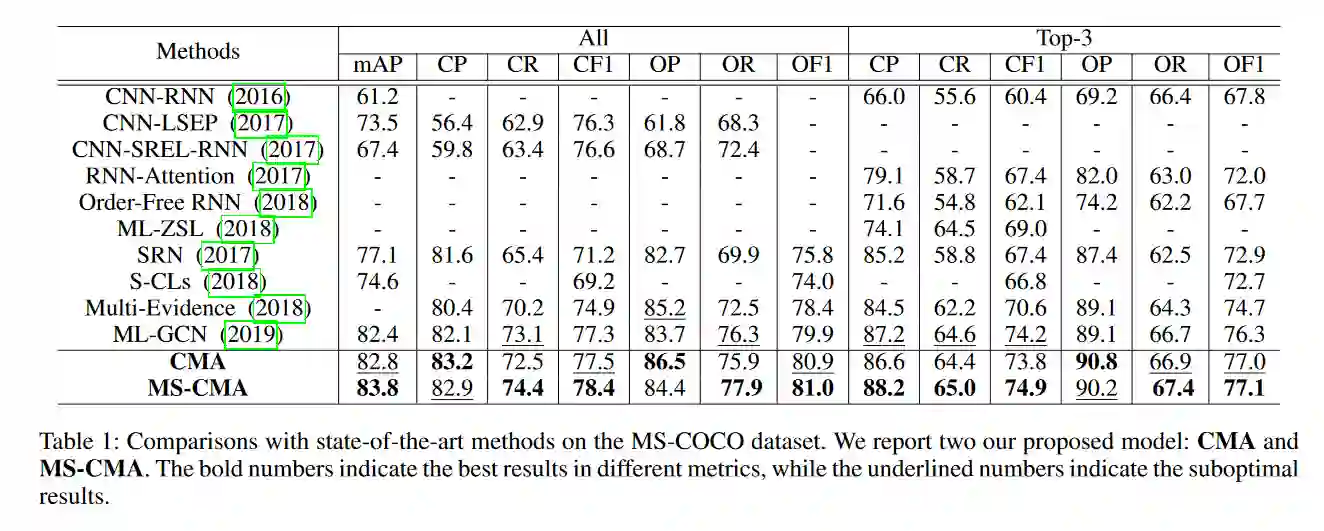
多标签图像和视频分类是计算机视觉中最基本也是最具挑战性的任务。主要的挑战在于捕获标签之间的空间或时间依赖关系,以及发现每个类的区别特征的位置。为了克服这些挑战,我们提出将语义图嵌入的跨模态注意用于多标签分类。基于所构造的标签图,我们提出了一种基于邻接的相似图嵌入方法来学习语义标签嵌入,该方法显式地利用了标签之间的关系。在学习标签嵌入的指导下,生成了新的跨模态注意图。在两个多标签图像分类数据集(MS-COCO和NUS-WIDE)上的实验表明,我们的方法优于其他现有的方法。此外,我们在一个大的多标签视频分类数据集上验证了我们的方法,评估结果证明了我们的方法的泛化能力。
成为VIP会员查看完整内容

相关内容
专知会员服务
99+阅读 · 2020年7月6日
专知会员服务
76+阅读 · 2020年1月16日
Arxiv
7+阅读 · 2018年5月24日



相关VIP内容
专知会员服务
99+阅读 · 2020年7月6日
专知会员服务
76+阅读 · 2020年1月16日
相关资讯
相关论文
Arxiv
7+阅读 · 2018年5月24日