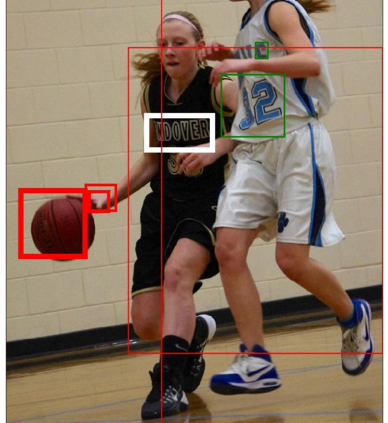
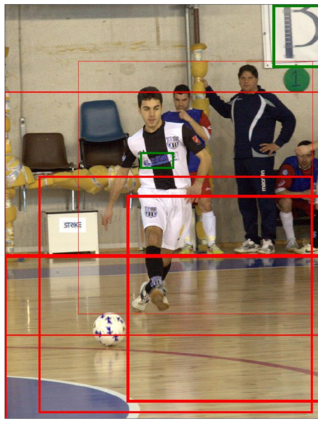
Answering questions that require reading texts in an image is challenging for current models. One key difficulty of this task is that rare, polysemous, and ambiguous words frequently appear in images, e.g., names of places, products, and sports teams. To overcome this difficulty, only resorting to pre-trained word embedding models is far from enough. A desired model should utilize the rich information in multiple modalities of the image to help understand the meaning of scene texts, e.g., the prominent text on a bottle is most likely to be the brand. Following this idea, we propose a novel VQA approach, Multi-Modal Graph Neural Network (MM-GNN). It first represents an image as a graph consisting of three sub-graphs, depicting visual, semantic, and numeric modalities respectively. Then, we introduce three aggregators which guide the message passing from one graph to another to utilize the contexts in various modalities, so as to refine the features of nodes. The updated nodes have better features for the downstream question answering module. Experimental evaluations show that our MM-GNN represents the scene texts better and obviously facilitates the performances on two VQA tasks that require reading scene texts.
翻译:需要用图像阅读文本的回答问题对于当前模型来说具有挑战性。 这项任务的关键困难之一是在图像中经常出现稀有、多元和模棱两可的单词,例如地点、产品和体育队的名称。 要克服这一困难,仅采用预先训练的嵌入字型就远远不够。 理想的模型应当利用图像中多种模式的丰富信息,帮助理解现场文本的含义,例如,瓶子上突出的文本很可能是品牌。 遵循这一想法,我们提出了一个新的VQA方法,即多式模型图像神经网络(MM-GNN),它首先代表由三个子图组成的图像图,分别描述视觉、语义和数字模式。 然后,我们引入三个聚合器,指导从一个图向另一个图传递信息,以不同方式利用背景,以便完善节点的特征。 更新的节点对下游解答模块具有更好的特征。 实验性评估显示,我们的M-GNNNU读文本代表了现场文本,明显地要求两个VQ的绩效。