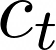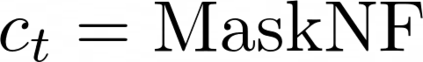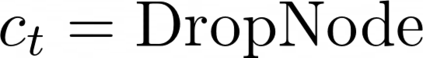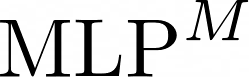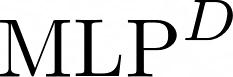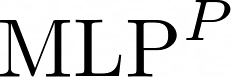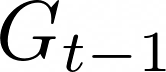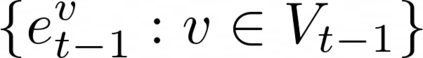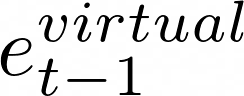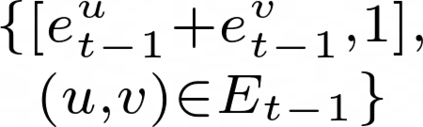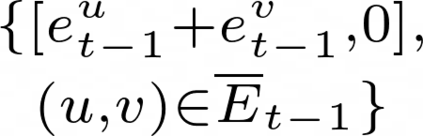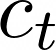Data augmentations are effective in improving the invariance of learning machines. We argue that the corechallenge of data augmentations lies in designing data transformations that preserve labels. This is relativelystraightforward for images, but much more challenging for graphs. In this work, we propose GraphAug, a novelautomated data augmentation method aiming at computing label-invariant augmentations for graph classification.Instead of using uniform transformations as in existing studies, GraphAug uses an automated augmentationmodel to avoid compromising critical label-related information of the graph, thereby producing label-invariantaugmentations at most times. To ensure label-invariance, we develop a training method based on reinforcementlearning to maximize an estimated label-invariance probability. Comprehensive experiments show that GraphAugoutperforms previous graph augmentation methods on various graph classification tasks.
翻译:数据增强对于改进学习机器的易变性是有效的。 我们认为,数据增强的核心挑战在于设计保护标签的数据转换。 这是相对偏向向图像,但对于图表则更具挑战性。 在这项工作中,我们提出GigapAug, 这是一种新颖的自动化数据增强方法,旨在计算标签易变性增强值以进行图表分类。GigapAug使用一个自动增强模型,而不是像现有研究那样使用统一转换,以避免损害图表中与标签有关的关键信息,从而在多数时候产生标签反差。为了确保标签反差,我们开发了一个基于强化学习的培训方法,以尽量扩大估计标签易变性概率。全面实验显示,GigapAug在各种图表分类任务中都采用了以前的图形增强方法。