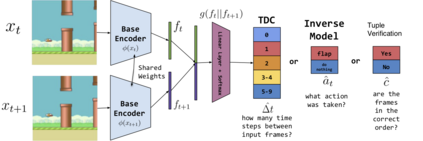
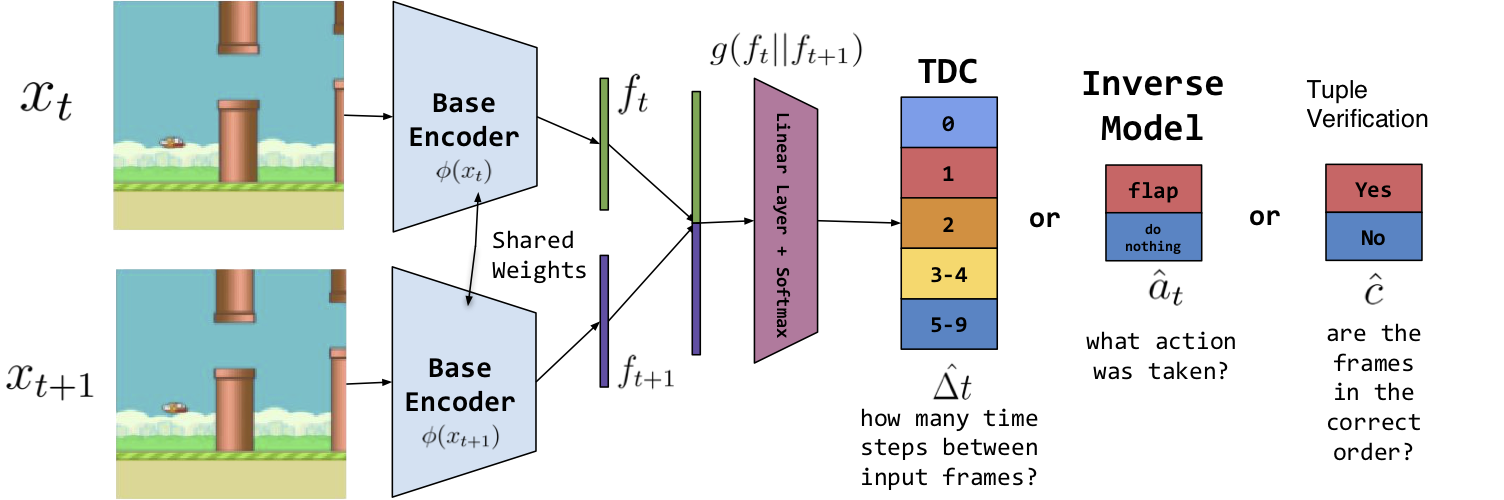
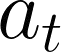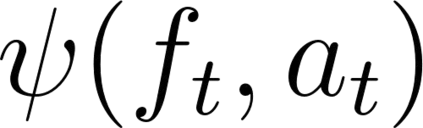Self-supervised methods, wherein an agent learns representations solely by observing the results of its actions, become crucial in environments which do not provide a dense reward signal or have labels. In most cases, such methods are used for pretraining or auxiliary tasks for "downstream" tasks, such as control, exploration, or imitation learning. However, it is not clear which method's representations best capture meaningful features of the environment, and which are best suited for which types of environments. We present a small-scale study of self-supervised methods on two visual environments: Flappy Bird and Sonic The Hedgehog. In particular, we quantitatively evaluate the representations learned from these tasks in two contexts: a) the extent to which the representations capture true state information of the agent and b) how generalizable these representations are to novel situations, like new levels and textures. Lastly, we evaluate these self-supervised features by visualizing which parts of the environment they focus on. Our results show that the utility of the representations is highly dependent on the visuals and dynamics of the environment.
翻译:在不提供密集的奖赏信号或贴标签的环境中,自我监督的方法,即代理人只通过观察其行动的结果来了解其表现,在这种环境中变得至关重要;在多数情况下,这种方法用于“下游”任务的培训前或辅助任务,例如控制、探索或模仿学习;然而,还不清楚哪种方法的表示方式最能捕捉环境的有意义的特征,最适合哪种环境类型。我们在两种视觉环境中对自我监督的方法进行了小规模的研究:飞禽和索尼奇猎鹰。我们尤其从两个角度对从这些任务中学到的表述进行了定量评价:(a) 表示方式获取代理人真实状况信息的程度,以及(b) 这些表述方式对于新情况的普遍程度,例如新的水平和纹理。最后,我们通过直观环境的哪个部分来评估这些自我监督特征。我们的结果表明,这些表述方式的效用在很大程度上取决于环境的视觉和动态。