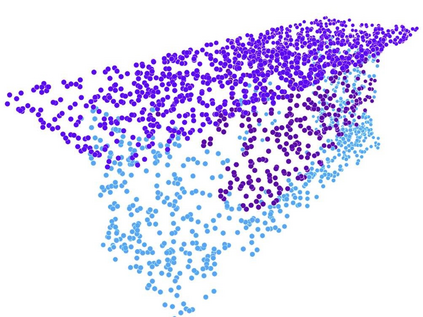
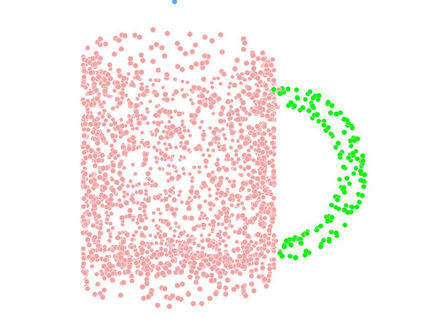
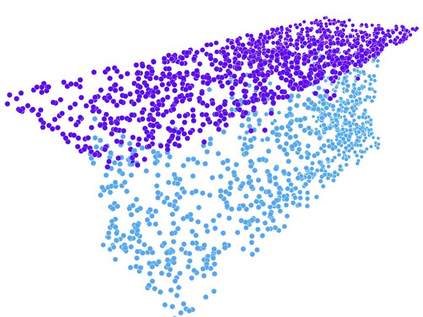
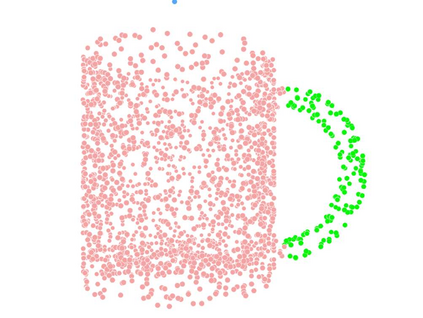
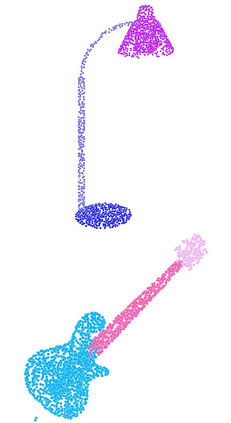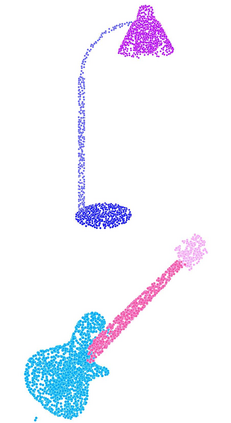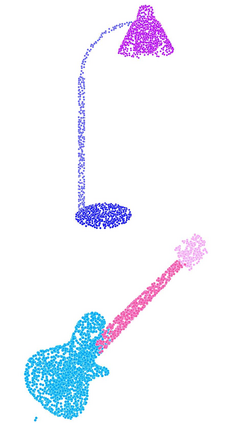Recent advances in Graph Convolutional Neural Networks (GCNNs) have shown their efficiency for non-Euclidean data on graphs, which often require a large amount of labeled data with high cost. It it thus critical to learn graph feature representations in an unsupervised manner in practice. To this end, we propose a novel unsupervised learning of Graph Transformation Equivariant Representations (GraphTER), aiming to capture intrinsic patterns of graph structure under both global and local transformations. Specifically, we allow to sample different groups of nodes from a graph and then transform them node-wise isotropically or anisotropically. Then, we self-train a representation encoder to capture the graph structures by reconstructing these node-wise transformations from the feature representations of the original and transformed graphs. In experiments, we apply the learned GraphTER to graphs of 3D point cloud data, and results on point cloud segmentation/classification show that GraphTER significantly outperforms state-of-the-art unsupervised approaches and pushes greatly closer towards the upper bound set by the fully supervised counterparts.
翻译:图表进化神经网络(GCNNS)最近的进展表明,它们对于图表上的非欧化神经网络(GCNNS)数据的效率很高,通常需要大量成本高的标签数据。因此,以不受监督的方式在实践中学习图形特征显示方式至关重要。为此,我们提议在无监督的情况下,对图表变形等离异表达式(Grapheter)进行新的、不受监督的学习,目的是在全球和地方变换中捕捉图形结构的内在模式。具体地说,我们允许从图表中抽取不同组的节点,然后将其转换为非非非异位或非亚学的。然后,我们自我培养一个代表编码器,从原始和变形图的特征显示中重建这些节点特性的变形,以捕捉图形结构。在实验中,我们将所学的图表应用于3D点云数据的图解,以及点云分化/级化结果显示,石墨大大超越了完全监督的对应方的状态、非超度方法,并大大逼近于上层。