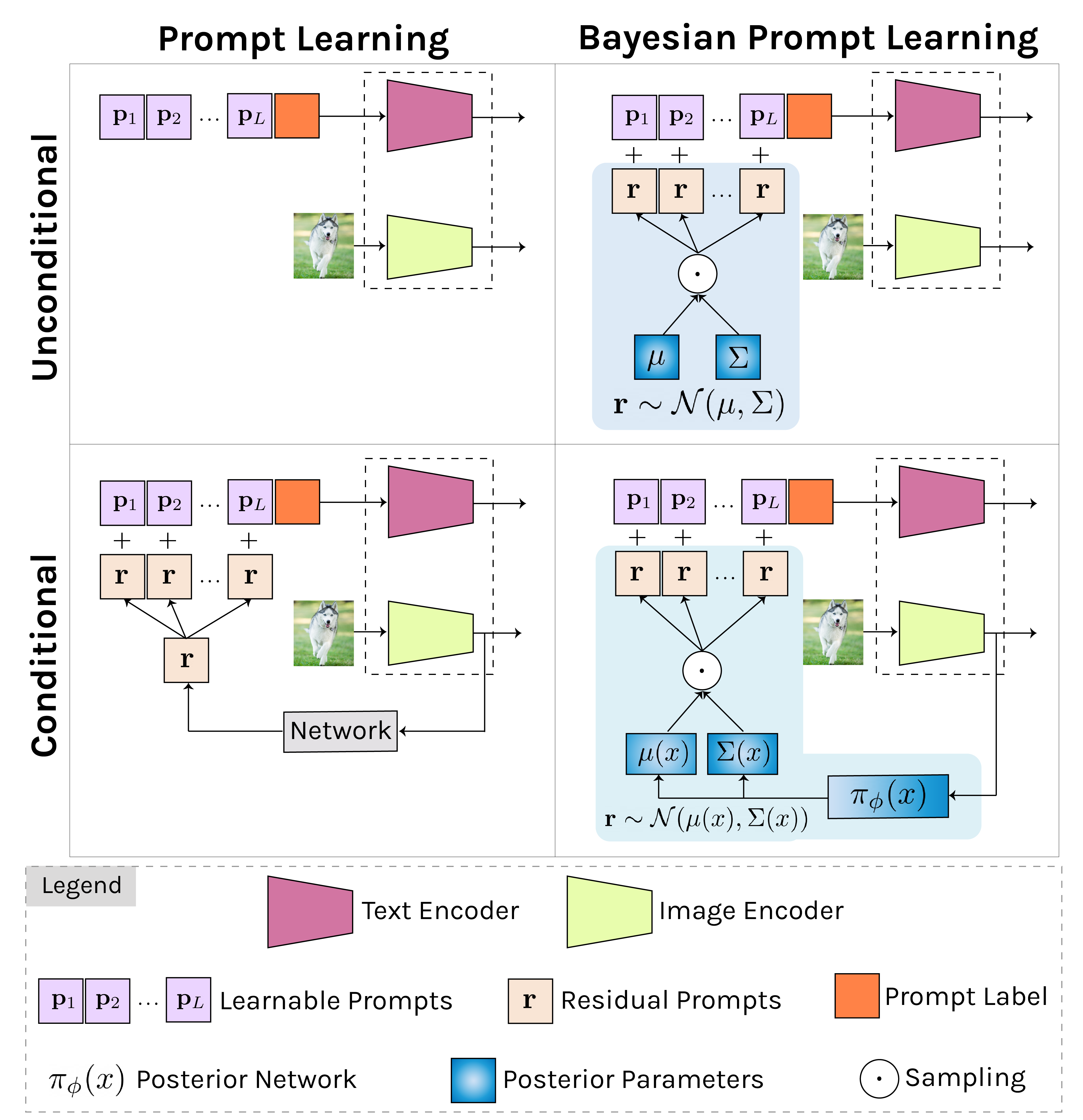
Foundational image-language models have generated considerable interest due to their efficient adaptation to downstream tasks by prompt learning. Prompt learning treats part of the language model input as trainable while freezing the rest, and optimizes an Empirical Risk Minimization objective. However, Empirical Risk Minimization is known to suffer from distributional shifts which hurt generalizability to prompts unseen during training. By leveraging the regularization ability of Bayesian methods, we frame prompt learning from the Bayesian perspective and formulate it as a variational inference problem. Our approach regularizes the prompt space, reduces overfitting to the seen prompts and improves the prompt generalization on unseen prompts. Our framework is implemented by modeling the input prompt space in a probabilistic manner, as an a priori distribution which makes our proposal compatible with prompt learning approaches that are unconditional or conditional on the image. We demonstrate empirically on 15 benchmarks that Bayesian prompt learning provides an appropriate coverage of the prompt space, prevents learning spurious features, and exploits transferable invariant features. This results in better generalization of unseen prompts, even across different datasets and domains.
翻译:基础图像语言模型由于通过迅速学习有效地适应下游任务而引起了相当大的兴趣。 快速学习将部分语言模型输入视为可训练的,同时冻结其余部分,并优化了经验风险最小化目标。 然而,据知,经验风险最小化会因分布性转移而受到影响,这种转移会损害一般的传播性,在培训期间会感知。 通过利用巴耶斯方法的正规化能力,我们从巴伊西亚角度将迅速学习设定为快速学习,并把它设计成一个变异推论问题。我们的方法规范了快速空间,减少对已见快的快感的过度适应,并改进了对看不见提示的快速普及。我们的框架是通过以概率化的方式模拟输入快速空间来实施的,作为一种事先的分布,使我们的建议与无条件或有条件于图像的迅速学习方法相匹配。 我们从15个基准上证明,巴伊西亚的快速学习对及时空间提供了适当的覆盖,防止学习欺骗性特征,并利用可转移的变异性特征。 其结果是,更全面地概括了无形的快感,甚至跨越不同的数据集和领域。</s>