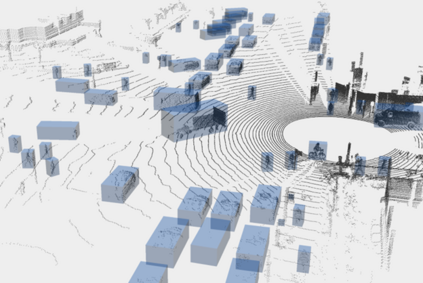
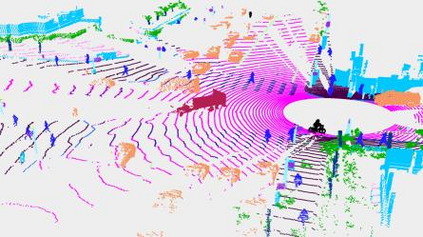
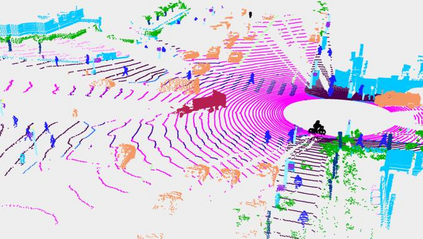
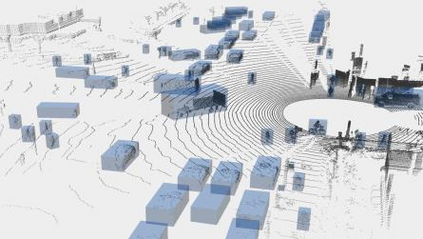
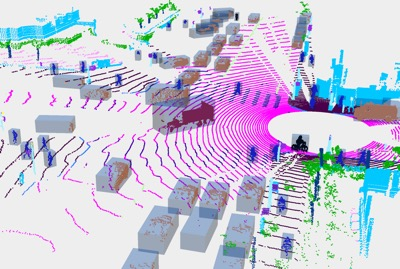
This technical report presents the 1st place winning solution for the Waymo Open Dataset 3D semantic segmentation challenge 2022. Our network, termed LidarMultiNet, unifies the major LiDAR perception tasks such as 3D semantic segmentation, object detection, and panoptic segmentation in a single framework. At the core of LidarMultiNet is a strong 3D voxel-based encoder-decoder network with a novel Global Context Pooling (GCP) module extracting global contextual features from a LiDAR frame to complement its local features. An optional second stage is proposed to refine the first-stage segmentation or generate accurate panoptic segmentation results. Our solution achieves a mIoU of 71.13 and is the best for most of the 22 classes on the Waymo 3D semantic segmentation test set, outperforming all the other 3D semantic segmentation methods on the official leaderboard. We demonstrate for the first time that major LiDAR perception tasks can be unified in a single strong network that can be trained end-to-end.
翻译:本技术报告展示了Waymo Open Dataset 3D 语义分解的挑战 2022 。 我们的网络名为 LidarMultiNet, 在一个单一框架内统一了3D 语义分解、 对象探测和全光分解等主要的利达雷达分解任务。 在利达尔MultiNet的核心是一个强大的 3D voxel 以 voxel 为基础的编码解析网络, 其新型全球背景集合模块从一个LiDAR 框架中提取全球背景特征, 以补充其本地特征 。 提议了一个可选的第二个阶段来改进第一阶段分解或产生准确的全光分解结果。 我们的解决方案实现了71.13 MIOU, 并且是Waymo 3D 语义分解测试组22个班中大多数班的最佳方法, 超过了官方领导板上所有其他 3D 语义分解方法 。 我们第一次证明, 主要的里达AR 语义分解任务可以在一个能够训练的单一强大的网络中统一一个端端端端端端端端端端端端的网络。