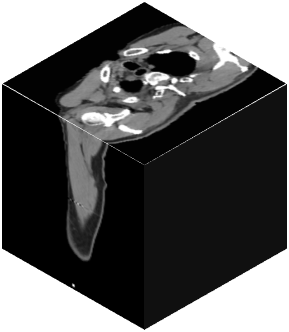
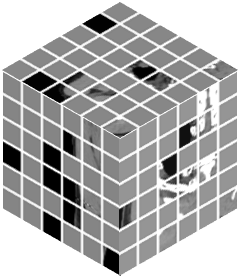
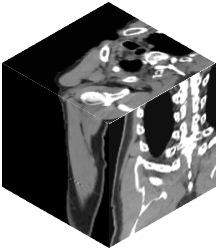
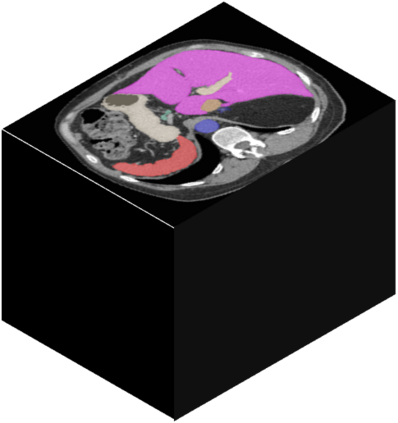
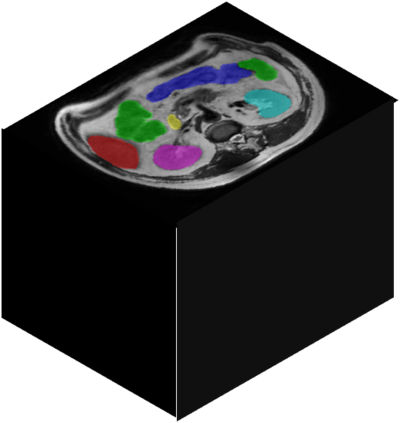
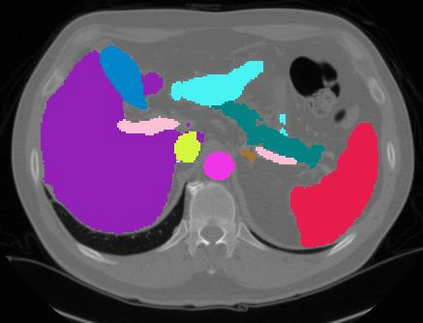
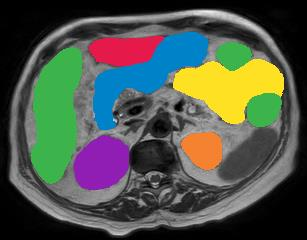
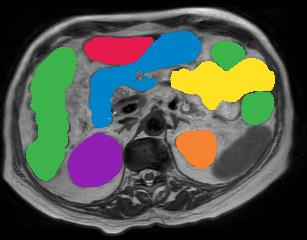
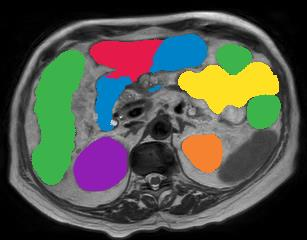
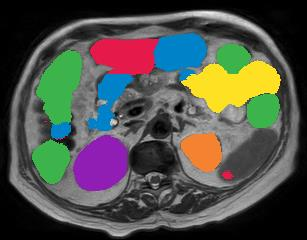
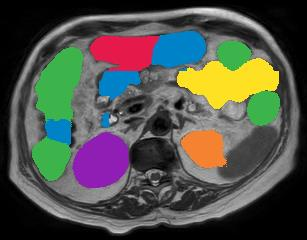
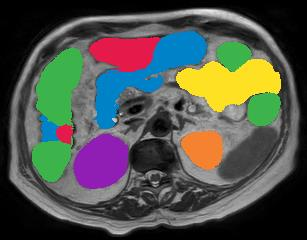
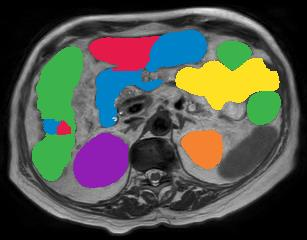
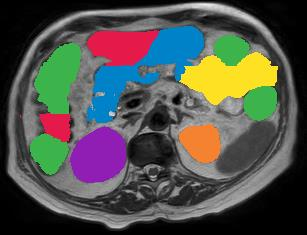
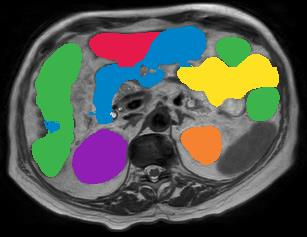
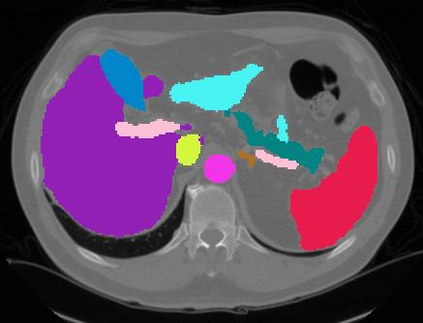
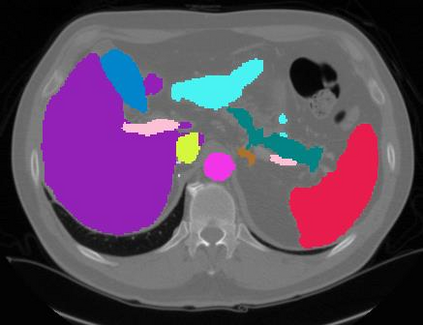
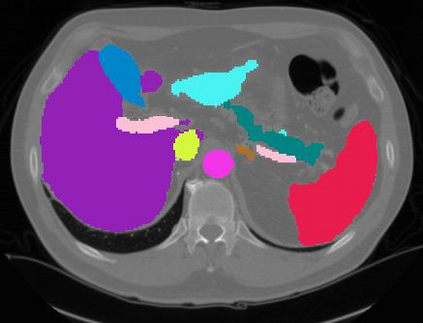
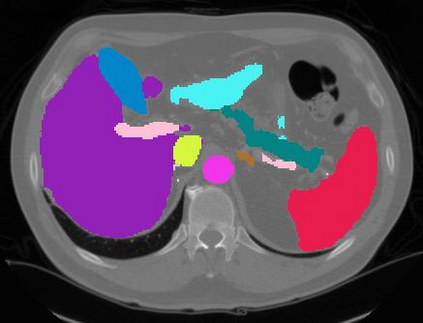
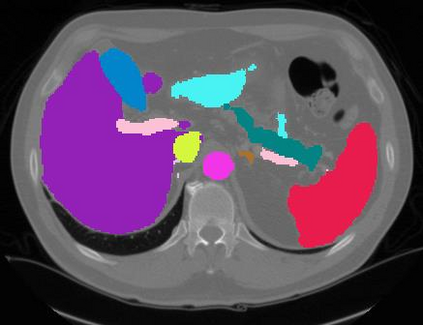
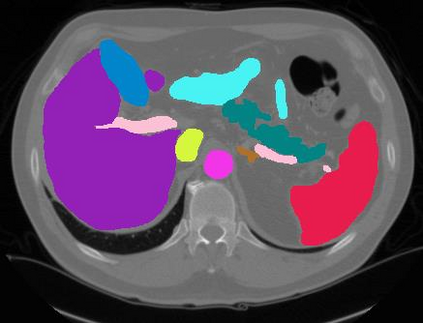
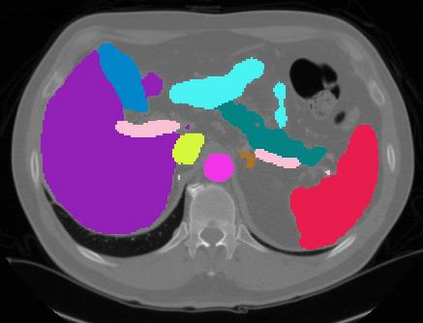
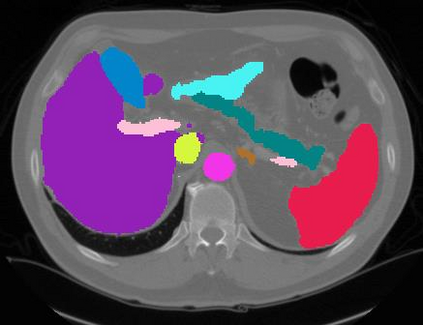
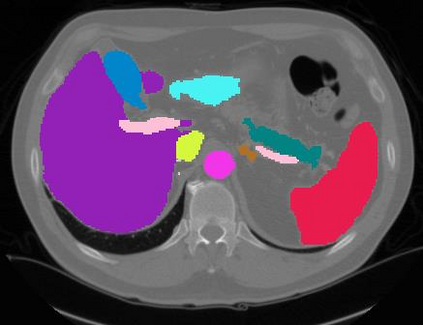
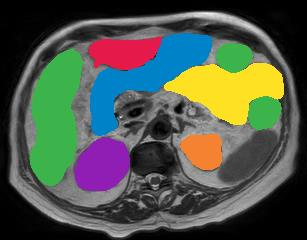
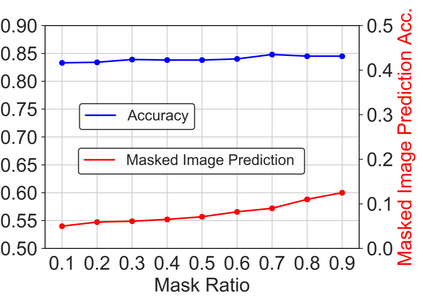
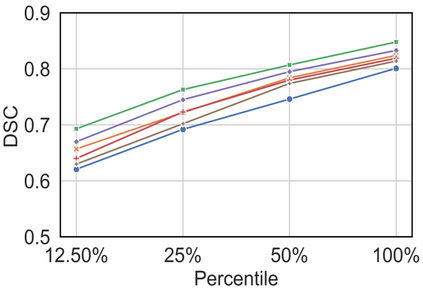
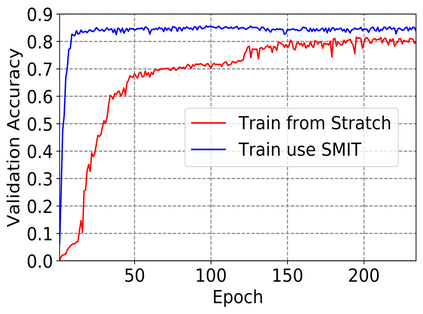
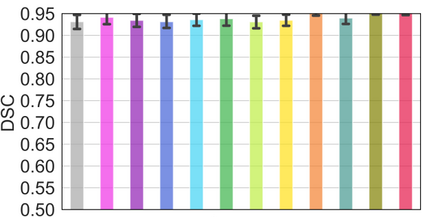
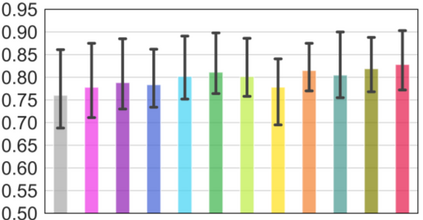
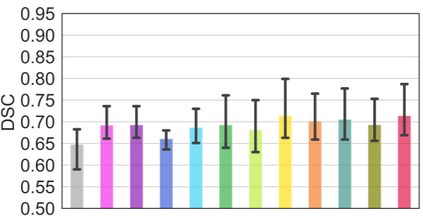
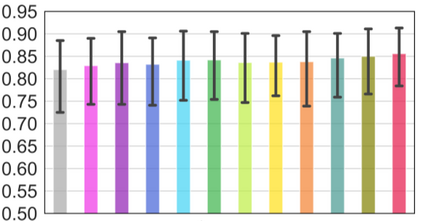
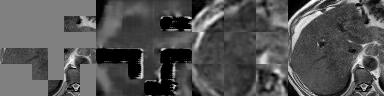
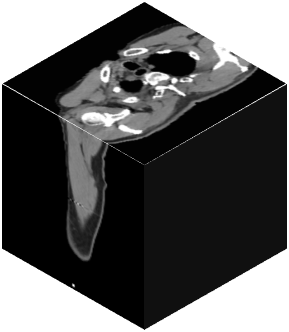
Vision transformers, with their ability to more efficiently model long-range context, have demonstrated impressive accuracy gains in several computer vision and medical image analysis tasks including segmentation. However, such methods need large labeled datasets for training, which is hard to obtain for medical image analysis. Self-supervised learning (SSL) has demonstrated success in medical image segmentation using convolutional networks. In this work, we developed a \underline{s}elf-distillation learning with \underline{m}asked \underline{i}mage modeling method to perform SSL for vision \underline{t}ransformers (SMIT) applied to 3D multi-organ segmentation from CT and MRI. Our contribution is a dense pixel-wise regression within masked patches called masked image prediction, which we combined with masked patch token distillation as pretext task to pre-train vision transformers. We show our approach is more accurate and requires fewer fine tuning datasets than other pretext tasks. Unlike prior medical image methods, which typically used image sets arising from disease sites and imaging modalities corresponding to the target tasks, we used 3,643 CT scans (602,708 images) arising from head and neck, lung, and kidney cancers as well as COVID-19 for pre-training and applied it to abdominal organs segmentation from MRI pancreatic cancer patients as well as publicly available 13 different abdominal organs segmentation from CT. Our method showed clear accuracy improvement (average DSC of 0.875 from MRI and 0.878 from CT) with reduced requirement for fine-tuning datasets over commonly used pretext tasks. Extensive comparisons against multiple current SSL methods were done. Code will be made available upon acceptance for publication.
翻译:视觉变异器能够更高效地模拟远程环境,在包括分解在内的若干计算机视觉和医学图像分析任务中显示出了令人印象深刻的准确性。 然而,这些方法需要大量的标签数据集用于培训,这是很难获得的医学图像分析。 自我监督的学习(SSL)已经展示了利用连锁网络在医学图像分解方面的成功。 在这项工作中,我们开发了一种通过下线{mr}sls}elf蒸馏学习的方法, 与直线{m}sdered\derline{i}rdeline{i}MCT 模型方法, 以执行用于当前和下线{troline{t}{t}r}ranserg 的 SSLSLS(SMIT), 用于3DD多机分解的 。 我们的贡献是:在蒙蔽的修补补补补补补补的图中, 以遮固的印印点为托辞, 与预感测变变的托任务相结合。 我们显示我们的方法更准确, 需要更精确地校正的调数据。