
标题:Self-Supervised Predictive Learning: A Negative-Free Method for Sound Source Localization in Visual Scenes
作者:Zengjie Song, Yuxi Wang, Junsong Fan, Zhaoxiang Zhang, Tieniu Tan
简介:
视觉和声音信号在物理世界常常相伴而生。一般而言,人可以“较为轻松地”将耳朵听到的声音和眼睛看到的物体一一对应起来,从而根据声音来定位发声物体。为实现这一类人行为智能,现有方法大多基于对比学习策略来构建图像和声音特征之间的对应关系。但这类方法均以随机采样的方式形成对比学习的负样本对,易引起不同模态特征之间的错误对齐,最终造成声源定位结果的混淆。
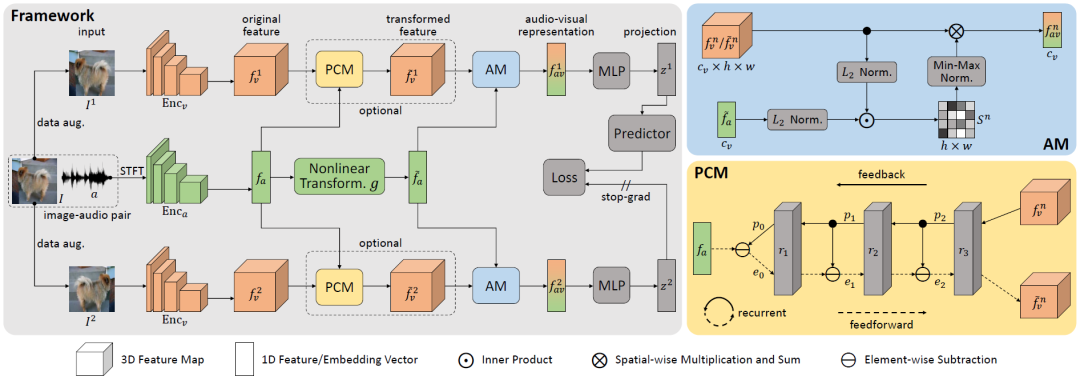
在本文中,我们提出了一种无需使用负样本的自监督学习方法,通过充分挖掘来自相同视频的视频帧图像和声音信号在特征水平上的相似性,来避免随机采样负样本引起的定位混淆问题。
为实现这一目的,我们首先设计了一个三分支深度网络,通过对同一视频帧图像进行数据增广,来构建声音特征与不同视角下的视觉特征之间的语义相关性;然后利用SimSiam式的自监督表示学习方法训练模型;最后,使用声音特征与视觉特征之间的相似性图确定声源位置。值得强调的是,提出的预测编码(Predictive Coding)模块有效实现了视觉模态和声音模态之间的特征对齐,有望拓展应用到其它多模态学习任务,如视觉-语言多模态。
在两个标准的声源定位数据集(SoundNet-Flickr和VGG-Sound Source)上进行的定量和定性实验表明,我们的方法在单声源定位任务上表现最优,证明了所提方法的有效性。
成为VIP会员查看完整内容

相关内容

专知会员服务
13+阅读 · 2022年3月19日
专知会员服务
87+阅读 · 2020年3月1日
专知会员服务
26+阅读 · 2020年2月16日
Arxiv
15+阅读 · 2020年3月31日



相关VIP内容
专知会员服务
13+阅读 · 2022年3月19日
专知会员服务
87+阅读 · 2020年3月1日
专知会员服务
26+阅读 · 2020年2月16日
相关资讯
相关论文
Arxiv
15+阅读 · 2020年3月31日