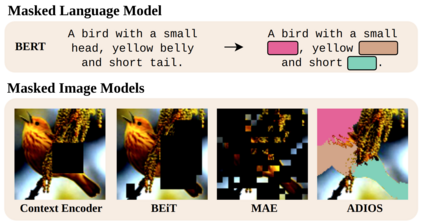
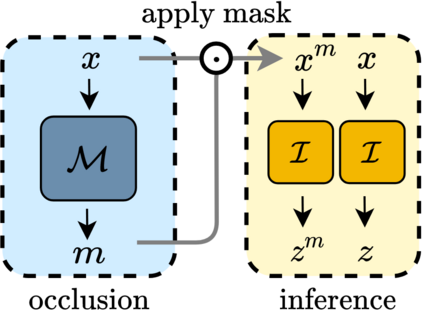
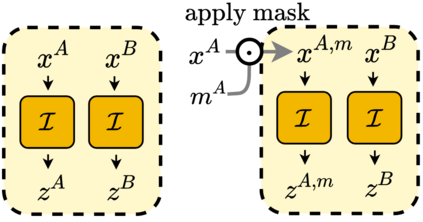
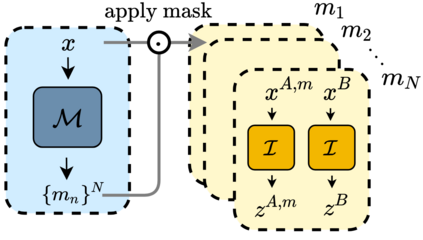
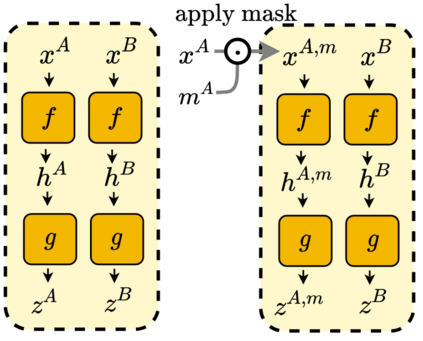
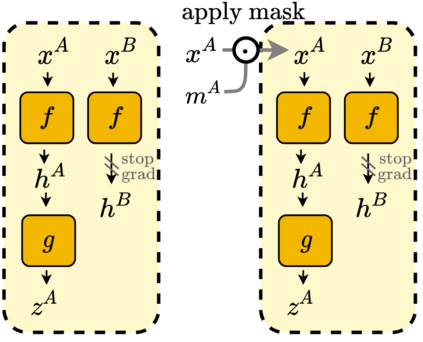
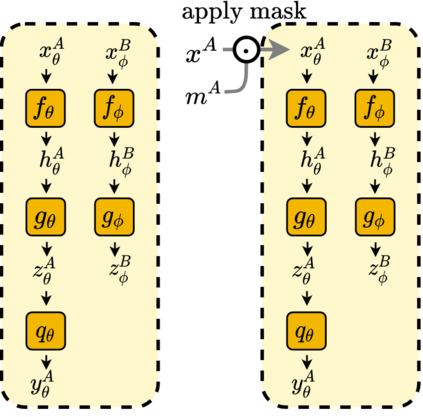
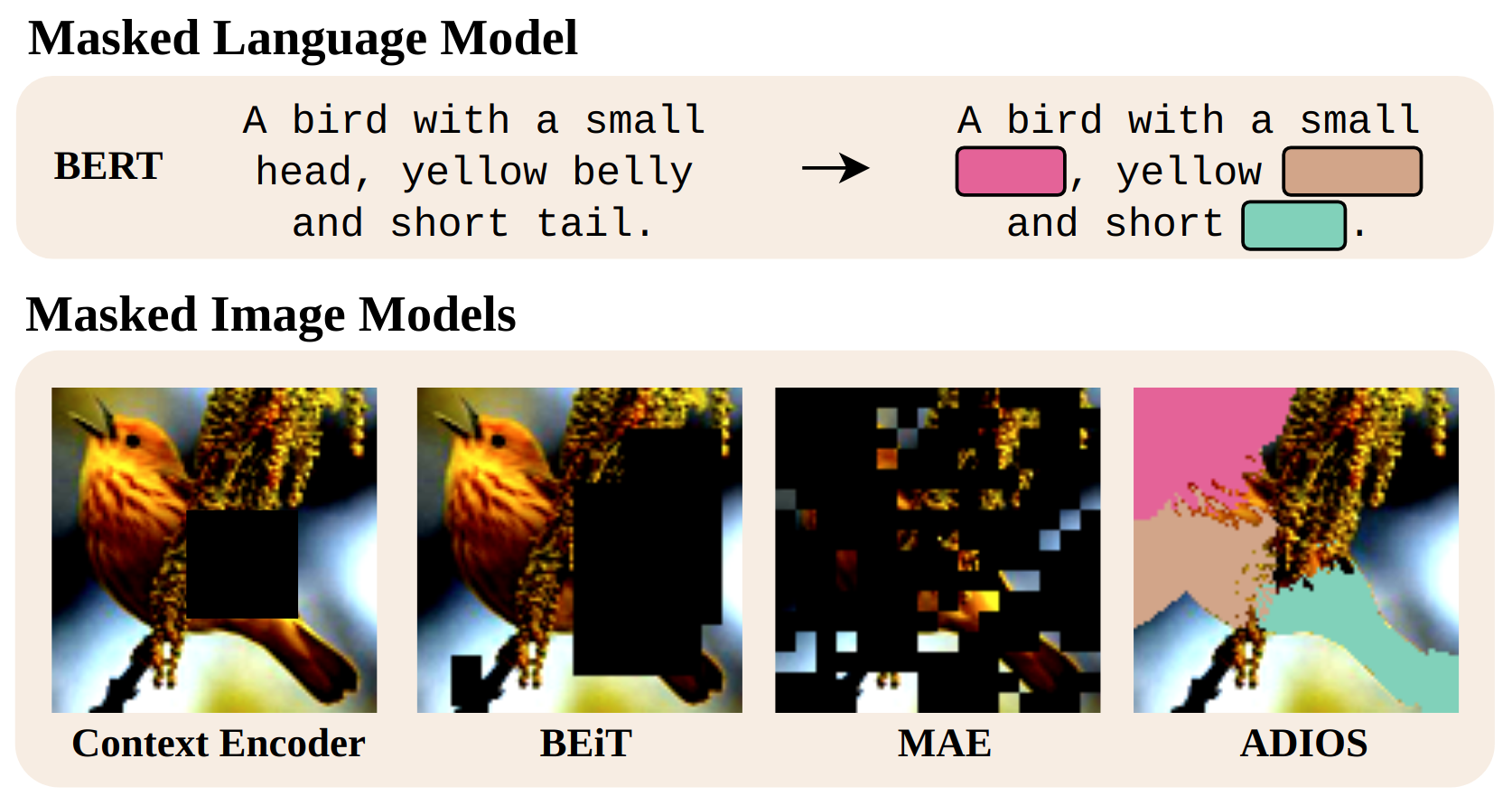
We propose ADIOS, a masked image model (MIM) framework for self-supervised learning, which simultaneously learns a masking function and an image encoder using an adversarial objective. The image encoder is trained to minimise the distance between representations of the original and that of a masked image. The masking function, conversely, aims at maximising this distance. ADIOS consistently improves on state-of-the-art self-supervised learning (SSL) methods on a variety of tasks and datasets -- including classification on ImageNet100 and STL10, transfer learning on CIFAR10/100, Flowers102 and iNaturalist, as well as robustness evaluated on the backgrounds challenge (Xiao et al., 2021) -- while generating semantically meaningful masks. Unlike modern MIM models such as MAE, BEiT and iBOT, ADIOS does not rely on the image-patch tokenisation construction of Vision Transformers, and can be implemented with convolutional backbones. We further demonstrate that the masks learned by ADIOS are more effective in improving representation learning of SSL methods than masking schemes used in popular MIM models. Code is available at https://github.com/YugeTen/adios.
翻译:我们提议ADIOS,这是一个自我监督学习的蒙面图像模型(MIM)框架,它同时使用对抗性目标学习遮面功能和图像编码器。图像编码器经过培训,以尽可能缩小原始图像与蒙面图像的表达方式之间的距离。相反,遮面功能旨在尽可能扩大这一距离。ADIOS在各种任务和数据集方面不断改进最先进的自我监督学习方法(SSL),包括图像网100和STL10分类,CIFAR10/100、Flowers102和iNaturalist的转移学习,以及背景挑战评估的稳健性(Xiao等人,2021),同时生成具有语义意义的面具。与现代MIM模型(如MAE、BeiT和iBOT)不同,ADIOS并不依赖愿景变异器的图像匹配象征性化构建,而是可以与革命性骨干一起实施。我们进一步证明,ADIOS所学的面具在使用MIMT/MLAMA的模型中,在改进MSLA/MA的通用模型中学习方法方面更为有效。