【论文推荐】最新5篇图像描述生成(Image Caption)相关论文—情感、注意力机制、遥感图像、序列到序列、深度神经结构
【导读】专知内容组整理了最近五篇图像描述生成(Image Caption)相关文章,为大家进行介绍,欢迎查看!
1. Image Captioning at Will: A Versatile Scheme for Effectively Injecting Sentiments into Image Descriptions(图像描述生成:一个有效地将情感结合到图像描述中的方案)
作者:Quanzeng You,Hailin Jin,Jiebo Luo
摘要:Automatic image captioning has recently approached human-level performance due to the latest advances in computer vision and natural language understanding. However, most of the current models can only generate plain factual descriptions about the content of a given image. However, for human beings, image caption writing is quite flexible and diverse, where additional language dimensions, such as emotion, humor and language styles, are often incorporated to produce diverse, emotional, or appealing captions. In particular, we are interested in generating sentiment-conveying image descriptions, which has received little attention. The main challenge is how to effectively inject sentiments into the generated captions without altering the semantic matching between the visual content and the generated descriptions. In this work, we propose two different models, which employ different schemes for injecting sentiments into image captions. Compared with the few existing approaches, the proposed models are much simpler and yet more effective. The experimental results show that our model outperform the state-of-the-art models in generating sentimental (i.e., sentiment-bearing) image captions. In addition, we can also easily manipulate the model by assigning different sentiments to the testing image to generate captions with the corresponding sentiments.
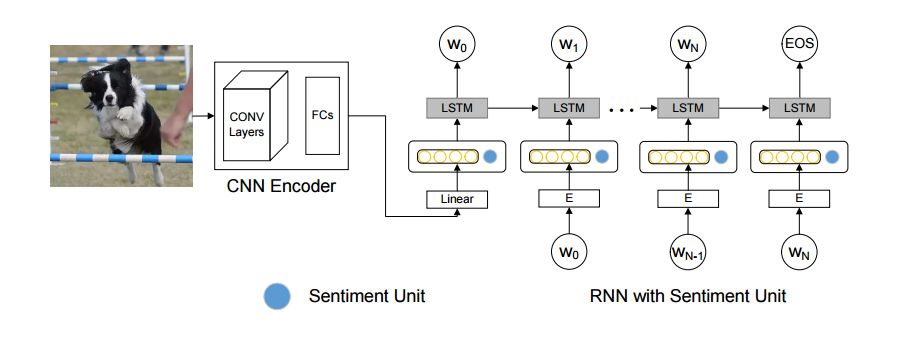
期刊:arXiv, 2018年1月31日
网址:
http://www.zhuanzhi.ai/document/71ae60a957ad68f4a80e330d05e67ef0
2. Order-Free RNN with Visual Attention for Multi-Label Classification(无序RNN与视觉注意力机制结合的多标签分类)
作者:Shang-Fu Chen,Yi-Chen Chen,Chih-Kuan Yeh,Yu-Chiang Frank Wang
摘要:In this paper, we propose the joint learning attention and recurrent neural network (RNN) models for multi-label classification. While approaches based on the use of either model exist (e.g., for the task of image captioning), training such existing network architectures typically require pre-defined label sequences. For multi-label classification, it would be desirable to have a robust inference process, so that the prediction error would not propagate and thus affect the performance. Our proposed model uniquely integrates attention and Long Short Term Memory (LSTM) models, which not only addresses the above problem but also allows one to identify visual objects of interests with varying sizes without the prior knowledge of particular label ordering. More importantly, label co-occurrence information can be jointly exploited by our LSTM model. Finally, by advancing the technique of beam search, prediction of multiple labels can be efficiently achieved by our proposed network model.
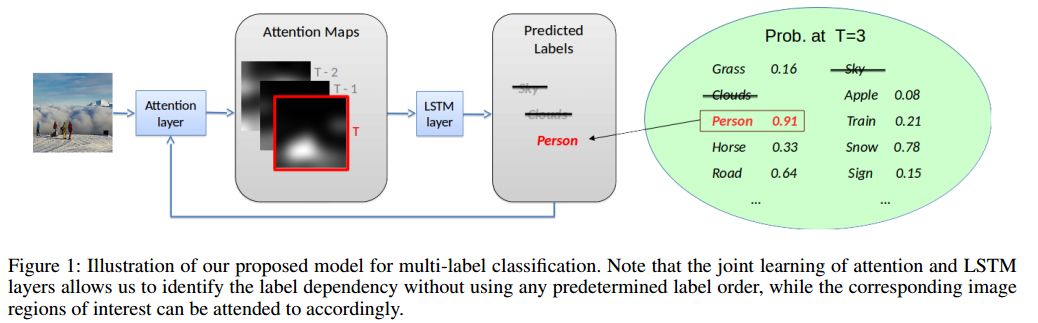
期刊:arXiv, 2017年12月20日
网址:
http://www.zhuanzhi.ai/document/0a34485f1b9e7e60314cc7ebe21d0add
3. Exploring Models and Data for Remote Sensing Image Caption Generation(探索遥感图像描述生成的模型和数据)
作者:Xiaoqiang Lu,Binqiang Wang,Xiangtao Zheng,Xuelong Li
摘要:Inspired by recent development of artificial satellite, remote sensing images have attracted extensive attention. Recently, noticeable progress has been made in scene classification and target detection.However, it is still not clear how to describe the remote sensing image content with accurate and concise sentences. In this paper, we investigate to describe the remote sensing images with accurate and flexible sentences. First, some annotated instructions are presented to better describe the remote sensing images considering the special characteristics of remote sensing images. Second, in order to exhaustively exploit the contents of remote sensing images, a large-scale aerial image data set is constructed for remote sensing image caption. Finally, a comprehensive review is presented on the proposed data set to fully advance the task of remote sensing caption. Extensive experiments on the proposed data set demonstrate that the content of the remote sensing image can be completely described by generating language descriptions. The data set is available at https://github.com/201528014227051/RSICD_optimal
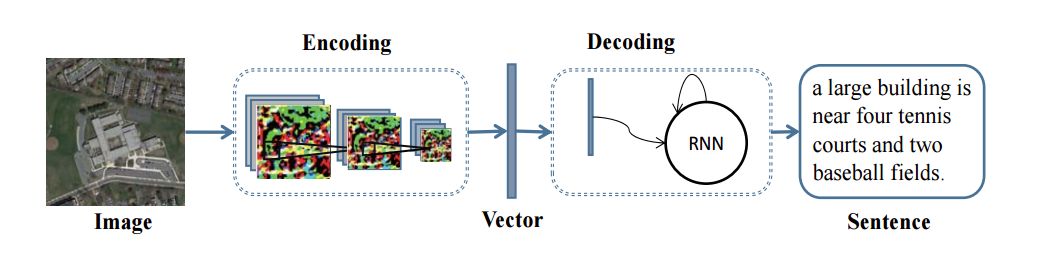
期刊:arXiv, 2017年12月21日
网址:
http://www.zhuanzhi.ai/document/33c9d18bd41a96f9df68d6364e2fb550
4. GeoSeq2Seq: Information Geometric Sequence-to-Sequence Networks(GeoSeq2Seq:信息几何序列到序列的网络)
作者:Alessandro Bay,Biswa Sengupta
摘要:The Fisher information metric is an important foundation of information geometry, wherein it allows us to approximate the local geometry of a probability distribution. Recurrent neural networks such as the Sequence-to-Sequence (Seq2Seq) networks that have lately been used to yield state-of-the-art performance on speech translation or image captioning have so far ignored the geometry of the latent embedding, that they iteratively learn. We propose the information geometric Seq2Seq (GeoSeq2Seq) network which abridges the gap between deep recurrent neural networks and information geometry. Specifically, the latent embedding offered by a recurrent network is encoded as a Fisher kernel of a parametric Gaussian Mixture Model, a formalism common in computer vision. We utilise such a network to predict the shortest routes between two nodes of a graph by learning the adjacency matrix using the GeoSeq2Seq formalism; our results show that for such a problem the probabilistic representation of the latent embedding supersedes the non-probabilistic embedding by 10-15\%.
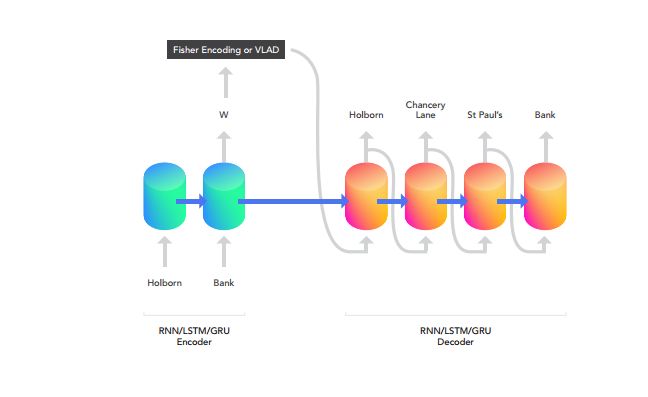
期刊:arXiv, 2018年1月6日
网址:
http://www.zhuanzhi.ai/document/448502417b54e0c13b89ee833489377c
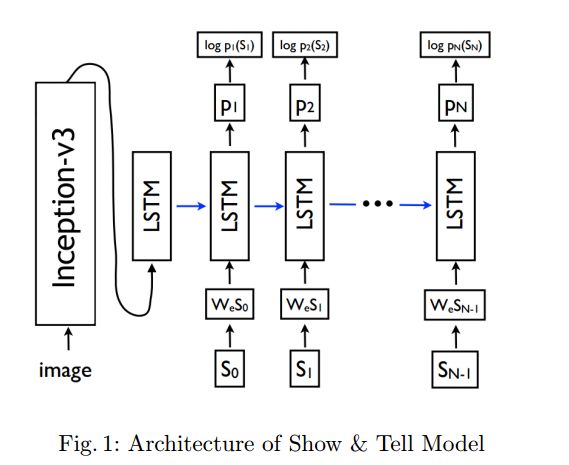
5. Image Captioning using Deep Neural Architectures(基于深度神经结构的图像描述生成)
作者:Parth Shah,Vishvajit Bakarola,Supriya Pati
摘要:Automatically creating the description of an image using any natural languages sentence like English is a very challenging task. It requires expertise of both image processing as well as natural language processing. This paper discuss about different available models for image captioning task. We have also discussed about how the advancement in the task of object recognition and machine translation has greatly improved the performance of image captioning model in recent years. In addition to that we have discussed how this model can be implemented. In the end, we have also evaluated the performance of model using standard evaluation matrices.
期刊:arXiv, 2018年1月17日
网址:
http://www.zhuanzhi.ai/document/d88e87447c9122fc4ef01738987f3f21
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!





