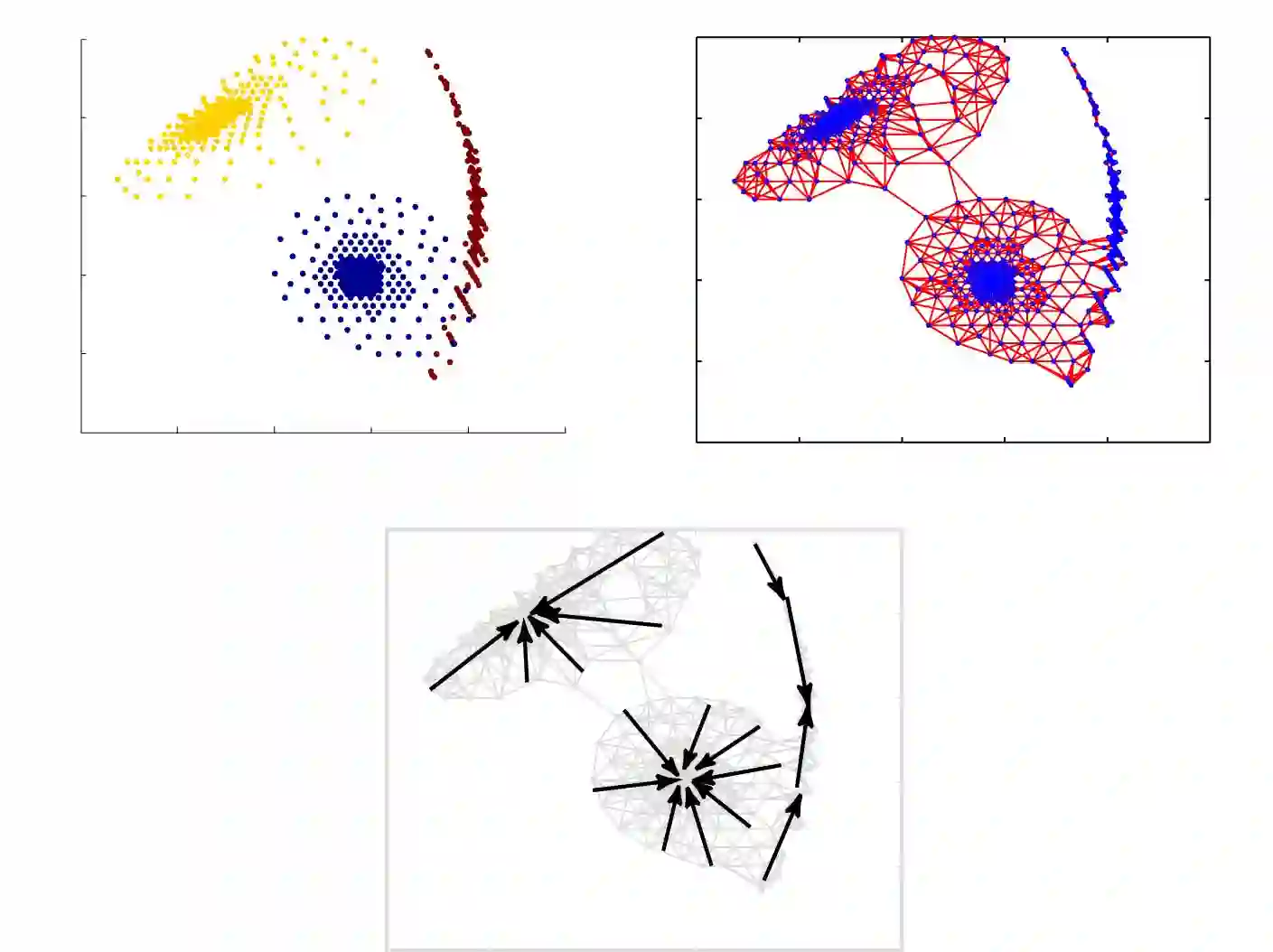
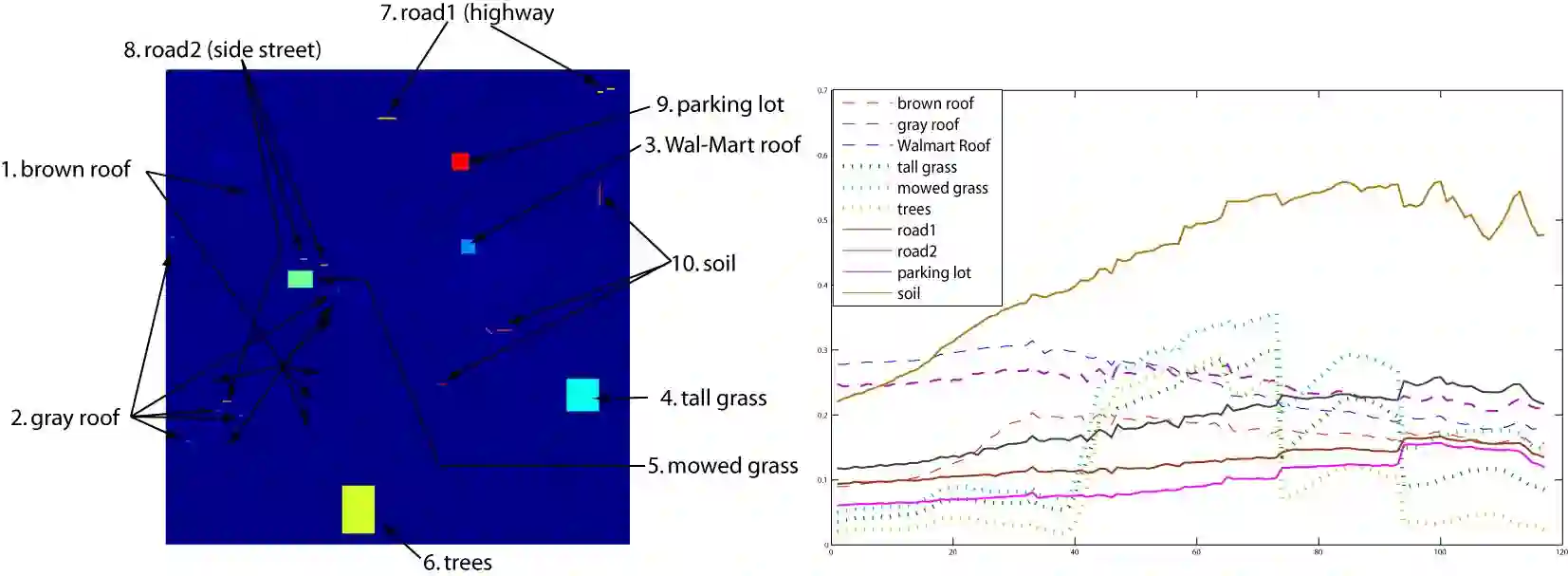
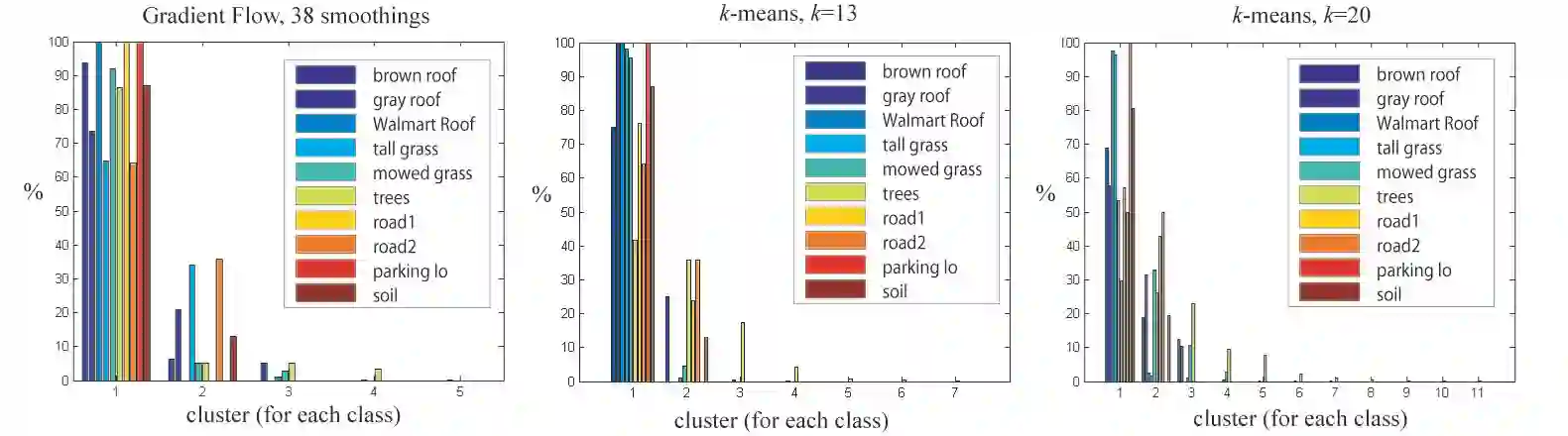
In this paper we present a new dynamical systems algorithm for clustering in hyperspectral images. The main idea of the algorithm is that data points are \`pushed\' in the direction of increasing density and groups of pixels that end up in the same dense regions belong to the same class. This is essentially a numerical solution of the differential equation defined by the gradient of the density of data points on the data manifold. The number of classes is automated and the resulting clustering can be extremely accurate. In addition to providing a accurate clustering, this algorithm presents a new tool for understanding hyperspectral data in high dimensions. We evaluate the algorithm on the Urban (Available at www.tec.ary.mil/Hypercube/) scene comparing performance against the k-means algorithm using pre-identified classes of materials as ground truth.
翻译:在本文中,我们提出了一个用于在超光谱图像中分组的新的动态系统算法。 算法的主要理念是,数据点是“ 推进”, 朝着增加密度和像素组的方向发展,最终在同一稠密地区,这些象素组属于同一类。 这基本上是数据方块中数据点密度梯度所定义的差别方程式的数值解决方案。 分类数是自动化的, 由此产生的组合可以非常精确。 除了提供准确的组合外, 该算法还提供了一个了解高维度超光谱数据的新工具。 我们评估城市的算法(可在www.tec.ary.mil/Hypercube/), 将业绩与使用预先确定的材料类别作为地面真理的k- 比例算法进行比较。