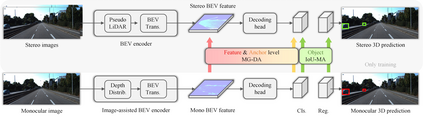
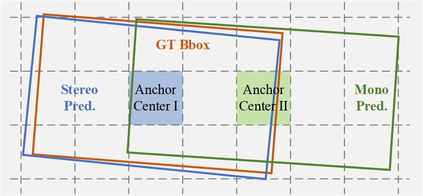
Monocular 3D object detection aims to predict the object location, dimension and orientation in 3D space alongside the object category given only a monocular image. It poses a great challenge due to its ill-posed property which is critically lack of depth information in the 2D image plane. While there exist approaches leveraging off-the-shelve depth estimation or relying on LiDAR sensors to mitigate this problem, the dependence on the additional depth model or expensive equipment severely limits their scalability to generic 3D perception. In this paper, we propose a stereo-guided monocular 3D object detection framework, dubbed SGM3D, adapting the robust 3D features learned from stereo inputs to enhance the feature for monocular detection. We innovatively present a multi-granularity domain adaptation (MG-DA) mechanism to exploit the network's ability to generate stereo-mimicking features given only on monocular cues. Coarse BEV feature-level, as well as the fine anchor-level domain adaptation, are both leveraged for guidance in the monocular domain.In addition, we introduce an IoU matching-based alignment (IoU-MA) method for object-level domain adaptation between the stereo and monocular predictions to alleviate the mismatches while adopting the MG-DA. Extensive experiments demonstrate state-of-the-art results on KITTI and Lyft datasets.
翻译:3D 单体物体探测旨在预测3D 空间的物体位置、尺寸和方向以及仅以单体图像表示的物体类别。由于2D 图像平面的深度信息严重不足,因此,3D 物体特征的定位、尺寸和方向构成巨大挑战。虽然存在利用隐蔽深度估计或依靠LiDAR传感器来缓解这一问题的方法,但对额外深度模型或昂贵设备的依赖严重限制了其可扩缩到通用的3D感知。在本文件中,我们提议采用立体制导的单体3D 物体探测框架,称为SGM3D,调整从立体输入中学会学到的强力3D特性,以加强单体探测特征。我们创新地展示了多层域适应机制,以利用网络生成仅在单体提示上提供的立体偏移特征的能力。Corse BEV 特性水平和精细的锁定层域适应,都用于在单体域域中提供指导。此外,我们还采用了基于IU的立体对立基3D的3D调校准调整(IU-IMMA 系统对目标级别数据进行升级),同时演示了基础数据级的MA-MGMGAS级数据升级的校准方法。