
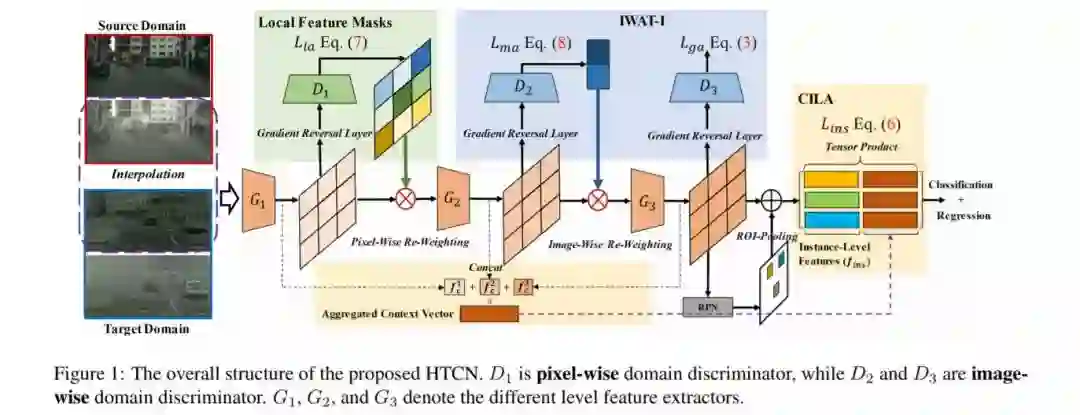
近年来,自适应目标检测的研究取得了令人瞩目的成果。尽管对抗性自适应极大地增强了特征表示的可迁移性,但对目标检测器的特征鉴别能力的研究却很少。此外,由于目标的复杂组合和域之间的场景布局的差异,在对抗性适应中,可迁移性和可辨别性可能会产生矛盾。本文提出了一种层级可迁移性校准网络(HTCN),该网络通过对特征表示的可迁移性进行分级(局部区域/图像/实例)校准来协调可迁移性和可识别性。该模型由三部分组成:(1)输入插值加权对抗性训练(iwati),通过重新加权插值后的图像级特征,增强了全局识别力;(2)上下文感知实例级对齐(context -aware Instance-Level Alignment, CILA)模块,该模块通过捕获实例级特征与实例级特征对齐的全局上下文信息之间的潜在互补效应,增强了局部识别能力;(3)校准局部可迁移性的局部特征掩码,为后续判别模式对齐提供语义指导。实验结果表明,在基准数据集上,HTCN的性能明显优于最先进的方法。
成为VIP会员查看完整内容
相关内容

专知会员服务
38+阅读 · 2020年3月23日
专知会员服务
39+阅读 · 2020年3月19日
专知会员服务
85+阅读 · 2019年11月15日

相关VIP内容
专知会员服务
38+阅读 · 2020年3月23日
专知会员服务
39+阅读 · 2020年3月19日
专知会员服务
85+阅读 · 2019年11月15日
相关资讯
相关论文