目标检测
·

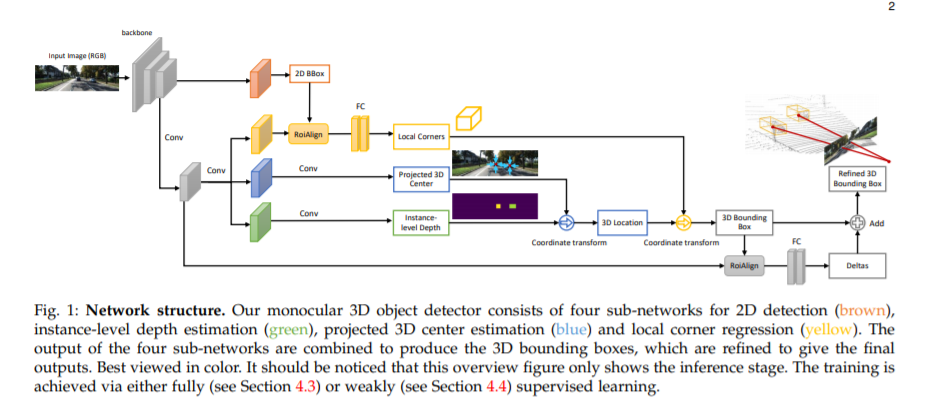
本文将单目3D目标检测任务分解为四个子任务,包括2D目标检测,实例级深度估计,投影3D中心估计和局部角点回归。
在真实的3D空间中检测和定位对象(在场景理解中起着至关重要的作用)尤其困难,因为在图像投影过程中由于几何信息的丢失,仅给出单目图像。我们提出MonoGRNet用于通过几何推理在观测到的2D投影和未观测到的深度尺寸中从单目图像中检测无模态3D对象。 MonoGRNet将单目3D目标检测任务分解为四个子任务,包括2D目标检测,实例级深度估计,投影3D中心估计和局部角点回归。任务分解极大地促进了单目3D对象检测,从而可以在单个前向传递中有效地预测目标3D边界框,而无需使用object proposal,后处理或先前方法所使用的计算上昂贵的像素级深度估计。此外,MonoGRNet可以灵活地适应完全和弱监督学习,从而提高了我们框架在各种环境中的可行性。在KITTI,Cityscapes和MS COCO数据集上进行了实验。结果表明,我们的框架在各种情况下均具有令人鼓舞的性能。
成为VIP会员查看完整内容
相关内容
专知会员服务
14+阅读 · 2020年6月18日
相关主题

相关VIP内容
专知会员服务
14+阅读 · 2020年6月18日
相关资讯
相关论文