【论文推荐】最新六篇视觉问答相关论文—深度嵌入学习、句子表征学习、深度特征聚合、3D匹配、细粒度文本摘要
【导读】专知内容组为大家推出近期六篇图像检索(Image Retrieval)相关论文,欢迎查看!
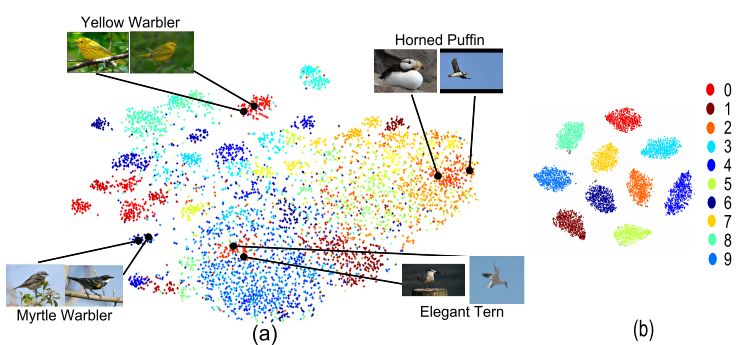
1.ALMN: Deep Embedding Learning with Geometrical Virtual Point Generating(ALMN:利用几何虚点生成的深度嵌入学习)
作者:Binghui Chen,Weihong Deng
机构:Beijing University of Posts and Telecommunications
摘要:Deep embedding learning becomes more attractive for discriminative feature learning, but many methods still require hard-class mining, which is computationally complex and performance-sensitive. To this end, we propose Adaptive Large Margin N-Pair loss (ALMN) to address the aforementioned issues. Instead of exploring hard example-mining strategy, we introduce the concept of large margin constraint. This constraint aims at encouraging local-adaptive large angular decision margin among dissimilar samples in multimodal feature space so as to significantly encourage intraclass compactness and interclass separability. And it is mainly achieved by a simple yet novel geometrical Virtual Point Generating (VPG) method, which converts artificially setting a fixed margin into automatically generating a boundary training sample in feature space and is an open question. We demonstrate the effectiveness of our method on several popular datasets for image retrieval and clustering tasks.
期刊:arXiv, 2018年6月5日
网址:
http://www.zhuanzhi.ai/document/f1dd2b6e23da582bd2560f818b0cf39c
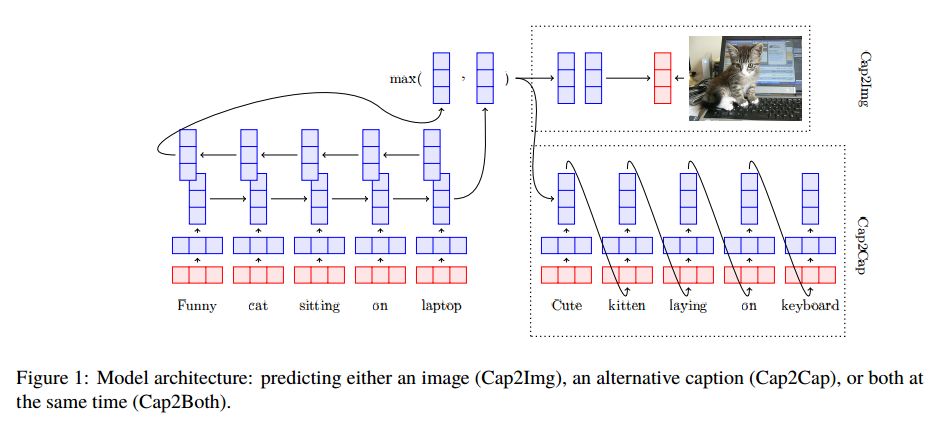
2.Learning Visually Grounded Sentence Representations(学习视觉基础的句子表征)
作者:Douwe Kiela,Alexis Conneau,Allan Jabri,Maximilian Nickel
机构:Facebook AI Research
摘要:We introduce a variety of models, trained on a supervised image captioning corpus to predict the image features for a given caption, to perform sentence representation grounding. We train a grounded sentence encoder that achieves good performance on COCO caption and image retrieval and subsequently show that this encoder can successfully be transferred to various NLP tasks, with improved performance over text-only models. Lastly, we analyze the contribution of grounding, and show that word embeddings learned by this system outperform non-grounded ones.
期刊:arXiv, 2018年6月5日
网址:
http://www.zhuanzhi.ai/document/d99a5a23ff3d79d6c44f357224fa52b3
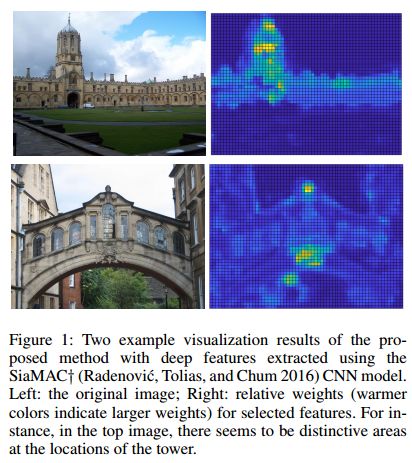
3.Deep Feature Aggregation with Heat Diffusion for Image Retrieval(基于热扩散深度特征聚合的图像检索)
作者:Shanmin Pang,Jin Ma,Jianru Xue,Jihua Zhu,Vicente Ordonez
机构:University of Virginia,Xi’an Jiaotong University
摘要:Image-level feature descriptors obtained from convolutional neural networks have shown powerful representation capabilities for image retrieval. In this paper, we present an unsupervised method to aggregate deep convolutional features into compact yet discriminative image vectors by simulating the dynamics of heat diffusion. A distinctive problem in image retrieval is that repetitive or bursty features tend to dominate feature representations, leading to less than ideal matches. We show that by considering each deep feature as a heat source, our method is able to avoiding over-representation of bursty features. We additionally provide a practical solution for the proposed aggregation method, which is further demonstrated in our experimental evaluation. Finally, we extensively evaluate the proposed approach with pre-trained and fine-tuned deep networks on common public benchmarks, and show superior performance compared to previous work.
期刊:arXiv, 2018年6月3日
网址:
http://www.zhuanzhi.ai/document/076d3c81489f0233b6b08d91efde1a82
4.Generative Adversarial Image Synthesis with Decision Tree Latent Controller(基于决策树潜在控制生成对抗的图像合成)
作者:Takuhiro Kaneko,Kaoru Hiramatsu,Kunio Kashino
摘要:This paper proposes the decision tree latent controller generative adversarial network (DTLC-GAN), an extension of a GAN that can learn hierarchically interpretable representations without relying on detailed supervision. To impose a hierarchical inclusion structure on latent variables, we incorporate a new architecture called the DTLC into the generator input. The DTLC has a multiple-layer tree structure in which the ON or OFF of the child node codes is controlled by the parent node codes. By using this architecture hierarchically, we can obtain the latent space in which the lower layer codes are selectively used depending on the higher layer ones. To make the latent codes capture salient semantic features of images in a hierarchically disentangled manner in the DTLC, we also propose a hierarchical conditional mutual information regularization and optimize it with a newly defined curriculum learning method that we propose as well. This makes it possible to discover hierarchically interpretable representations in a layer-by-layer manner on the basis of information gain by only using a single DTLC-GAN model. We evaluated the DTLC-GAN on various datasets, i.e., MNIST, CIFAR-10, Tiny ImageNet, 3D Faces, and CelebA, and confirmed that the DTLC-GAN can learn hierarchically interpretable representations with either unsupervised or weakly supervised settings. Furthermore, we applied the DTLC-GAN to image-retrieval tasks and showed its effectiveness in representation learning.

期刊:arXiv, 2018年5月27日
网址:
http://www.zhuanzhi.ai/document/58d6389427e946c03a81a01a838c3c26
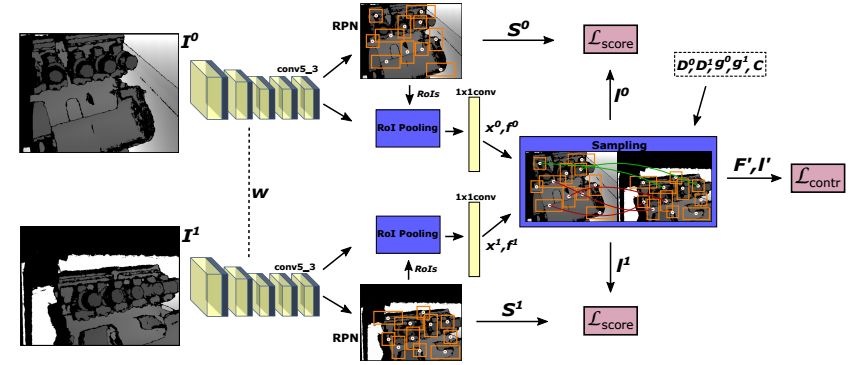
5.End-to-end learning of keypoint detector and descriptor for pose invariant 3D matching(对姿态不变性3D匹配的关键点检测器和描述的端到端学习)
作者:Georgios Georgakis,Srikrishna Karanam,Ziyan Wu,Jan Ernst,Jana Kosecka
机构:King Abdullah University of Science and Technology
摘要:Finding correspondences between images or 3D scans is at the heart of many computer vision and image retrieval applications and is often enabled by matching local keypoint descriptors. Various learning approaches have been applied in the past to different stages of the matching pipeline, considering detector, descriptor, or metric learning objectives. These objectives were typically addressed separately and most previous work has focused on image data. This paper proposes an end-to-end learning framework for keypoint detection and its representation (descriptor) for 3D depth maps or 3D scans, where the two can be jointly optimized towards task-specific objectives without a need for separate annotations. We employ a Siamese architecture augmented by a sampling layer and a novel score loss function which in turn affects the selection of region proposals. The positive and negative examples are obtained automatically by sampling corresponding region proposals based on their consistency with known 3D pose labels. Matching experiments with depth data on multiple benchmark datasets demonstrate the efficacy of the proposed approach, showing significant improvements over state-of-the-art methods.
期刊:arXiv, 2018年5月9日
网址:
http://www.zhuanzhi.ai/document/73324fe75bfb78f2f64a1893fc1824a0
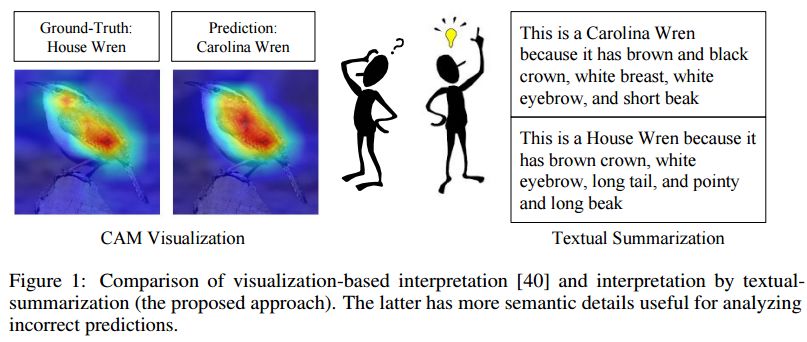
6.Neural Network Interpretation via Fine Grained Textual Summarization(基于细粒度文本摘要的神经网络解释)
作者:Pei Guo,Connor Anderson,Kolten Pearson,Ryan Farrell
机构:Brigham Young University
摘要:Current visualization based network interpretation methodssuffer from lacking semantic-level information. In this paper, we introduce the novel task of interpreting classification models using fine grained textual summarization. Along with the label prediction, the network will generate a sentence explaining its decision. Constructing a fully annotated dataset of filter|text pairs is unrealistic because of image to filter response function complexity. We instead propose a weakly-supervised learning algorithm leveraging off-the-shelf image caption annotations. Central to our algorithm is the filter-level attribute probability density function (PDF), learned as a conditional probability through Bayesian inference with the input image and its feature map as latent variables. We show our algorithm faithfully reflects the features learned by the model using rigorous applications like attribute based image retrieval and unsupervised text grounding. We further show that the textual summarization process can help in understanding network failure patterns and can provide clues for further improvements.
期刊:arXiv, 2018年5月23日
网址:
http://www.zhuanzhi.ai/document/dc0d8de3b87a59dd5a168d6299559c3a
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知

