Self-Attention 加速方法一览:ISSA、CCNet、CGNL、Linformer

极市导读
Self-attention机制是神经网络的研究热点之一。本文从self-attention的四个加速方法:ISSA、CCNe、CGNL、Linformer 分模块详细说明,辅以论文的思路说明。>>加入极市CV技术交流群,走在计算机视觉的最前沿
Attention 机制最早在NLP 领域中被提出,基于attention 的transformer结构近年在NLP的各项任务上大放异彩。在视觉任务中,attention也收到了很多的关注,比较有名的方法包括Non-Local Network,能够在时空volume中对全局的关系进行建模,获得了很好的效果。但视觉任务中的self-attention模块通常需要进行大矩阵的矩阵乘法,显存占用大且比较耗时。所以近年有许多优化self-attention模块速度的方法,这篇笔记主要讨论几篇相关方法,有错误之处欢迎指正。
Self-Attention 简介
Attention 机制通常可以表达为如下的形式
其中, 为query, 为key, 为value。从检索任务的角度来看,query是要检索的内容,key是索引,value则是待检索的值。attention的过程就是计算query 和key之间的相关性,获得attention map,再基于attention map去获得value中的特征值。而在如下图所示的self-attention中,Q K V均为同一个feature map。
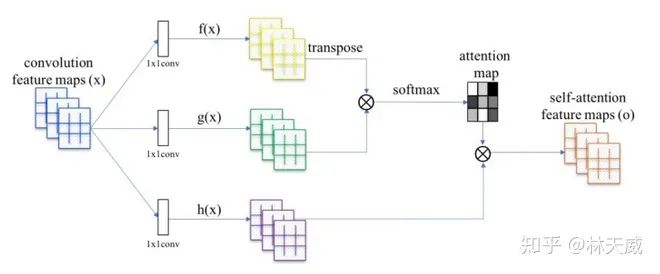
上图是一个self-attention模块的基本结构,输入为 , 分别通过1x1卷积获得 和 (记 )。则可以获得attention map为 。最后与 做矩阵乘法获得与输入shape想同的self-attention feature map。
在self-attention中,计算量和显存占用比较大的主要是生成attention map时的 和 最后的 两个步骤。对于64大小的feature map, 的大小为 。因此,self-attention 模块通常放在分辨率较低的网络后半段特征。
如何了优化attention的显存和计算量效率内,今天介绍的方法主要有两个方向的思路:
-
改变attention的形式,避免直接全图attention
-
Long + Short range attention:Interlaced Sparse Self-Attention -
水平+垂直attention:Ccnet: Criss-cross attention for semantic segmentation -
A2-Nets: Double Attention Networks -
降低attention计算过程中的某个维度
-
降低N维度:Linformer: Self-Attention with Linear Complexity -
降低C维度:常用方法了,通常就是C/2 或者C/4 -
其他
-
优化GNL:Compact generalized non-local network
Attention 形式优化
ISSA: Interlaced Sparse Self-Attention
-
论文基本思路:这篇论文的基本思路是“交错”。如下图所示,首先通过permute将feature以一定规律打乱,然后将feature map分为几个块分别做self-attention,这样获得的是long-range 的attention信息;此后,再进行一次permute还原回原来的特征位置,再次进行分块attention,获得了short-range 的attention。通过拆解long/short range的attention,能够大大降低计算量。
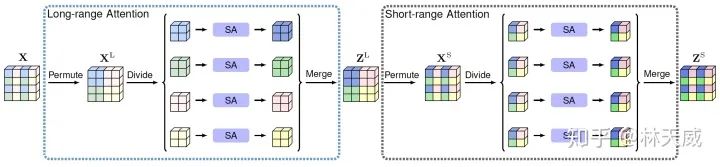
-
具体的性能表现如下图所示,可以看出,下降最明显的是显存的占用,主要是因为避免了attention过程中的大矩阵。而由于permute,divide等操作虽然不占flop,但是在inference的时候需要一定的时间,所以实际速度没有flops提升的那么多。不过总体而言,在效果没有明显下降的前提下,这个速度/显存的优化已经很优秀了。
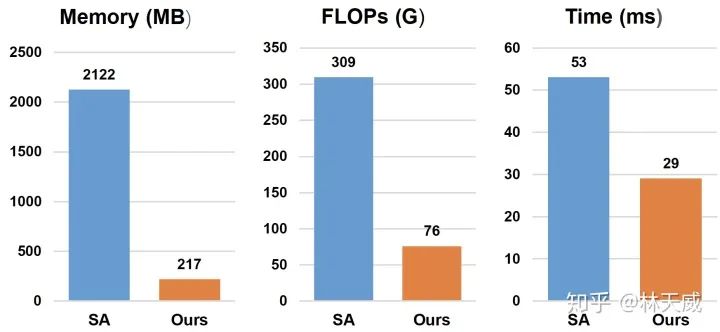
-
这篇文章在看的时候感觉既视感好强,后来想到这不就是hw上的shufflenet嘛。
CCNet: Criss-cross attention for semantic segmentation
-
论文主要思路:区别与Non-Local 中的全局attention,这篇文章提出只在特征点所对应的十字上进行attention。从而将复杂度从 降低到
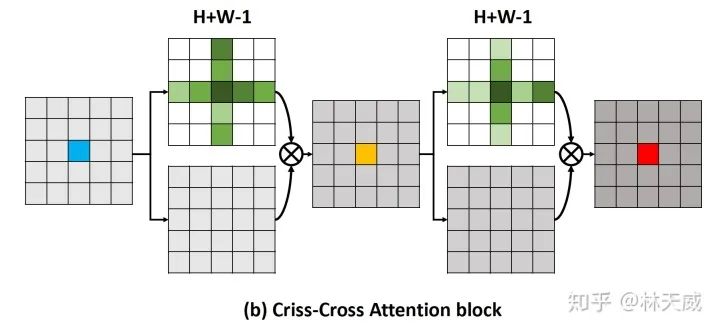
-
CCNet 的具体做法是,对于 上的一个点 ,我们都可以得到对应的特征向量 ,对于这个点对应的十字形区域,我们可以从 中提取对应的特征,构成 ,针对 和 进行矩阵乘法,则可以得到attention map 为 。最后对 以同样的方式提取十字形特征并进行矩阵乘法,则可以得到最后的结果。
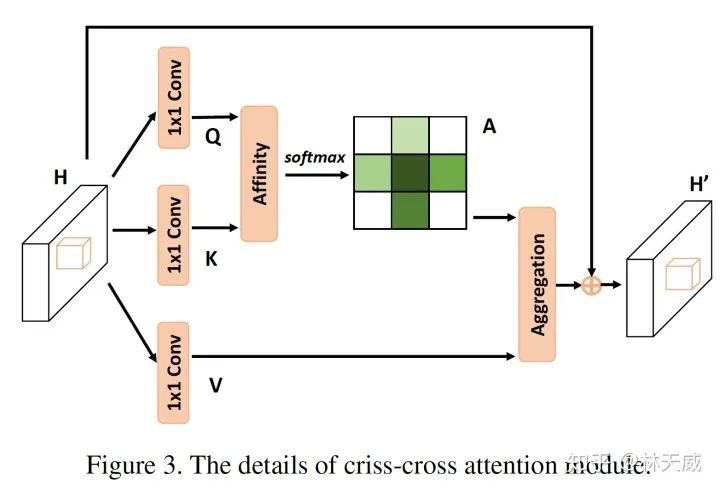
-
那么如何从十字attention过渡到全局attention呢,方法其实很简单,只需要做两次十字attention,每个点就可以获得全局的信息了。
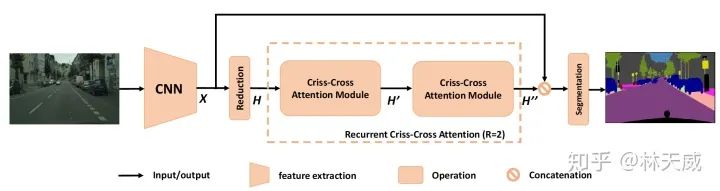
-
CCNet 的理论计算量(Flops and memory)比起Non-Local 是很有优势的。但是提取十字形特征这一步的效率可能并不是很高,论文中也并没有放出具体的代码实现。
A2-Nets: Double Attention Networks
-
这篇论文的attention 方式看下图即可
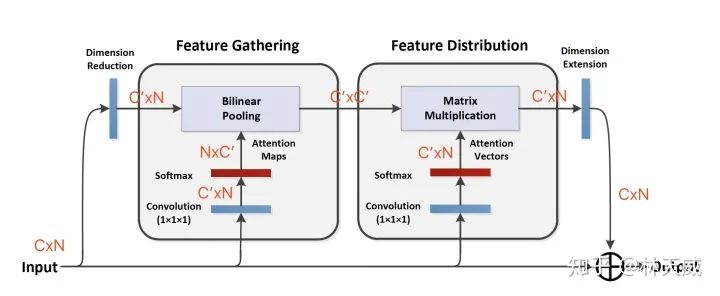
-
第一个 feautre gathering,可以理解为对每个channel,softmax找到最重要的位置,再去gathering所有channel上这个最重要位置上的特征;得到 CxC -
第二个 feautre distribution,可以理解为对每个channel,softmax找到最重要的位置,然后给每个channel的这个位置都分配一遍特征。 -
这篇文章的attention 方式很有趣,值得仔细琢磨一下的。不过速度方面比起NL应该没有提升特别多。
Attention 维度优化
Linformer: Self-Attention with Linear Complexity
-
Attention的过程如上所说,可以看作是 ,这篇文章对N做降维,将attention 转化为 ,在K是定值的情况下,既将复杂度从 降低到了 -
这篇文章大部分的篇幅,是在证明这样降低维度和原来的结果是近似的,没看太懂证明部分 -
实验部分,K取得越大效果越好,但是并不明显。即降维会非常略微地影响效果,同时非常有效地提升速度。
其他
CGNL: Compact generalized non-local network
这篇文章主要是来优化一种计算量更大的Self-attention方法:Generalized Non-local (GNL)。这种方法不仅做H W两个spatial尺度上的non-local attention,还额外考虑了C维度。因此复杂度是 。

这篇文章的主要思路是:利用泰勒展开,将 _ 近似成了 _ 。从而可以通过先计算后两项,将复杂度从 降低到了

-
这篇文章在视频理解、目标检测等任务上的实验效果都还不错,但是并没有给出速度方面的实验结果和分析。
推荐阅读






