
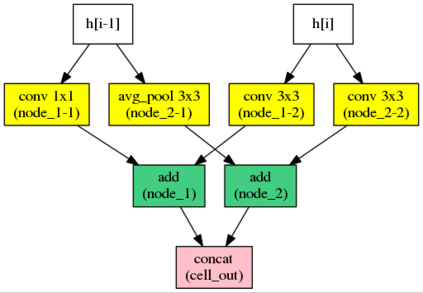
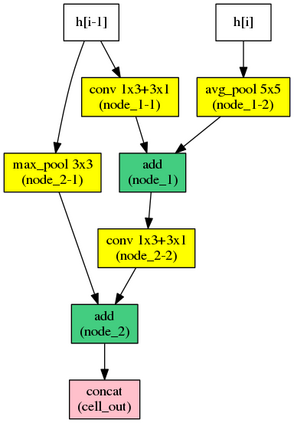
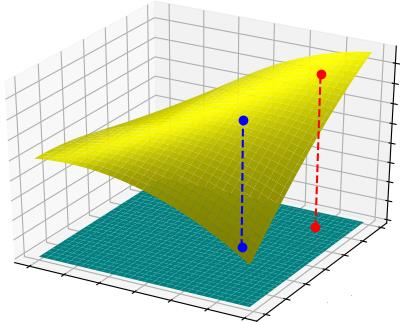
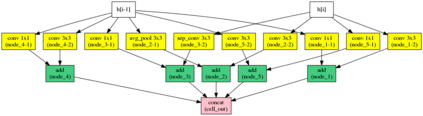
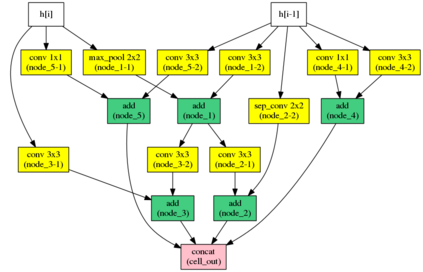
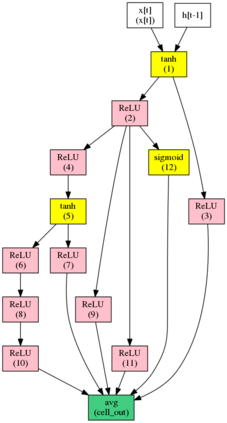
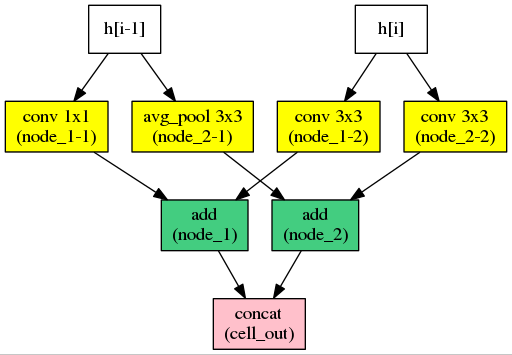
Automatic neural architecture design has shown its potential in discovering powerful neural network architectures. Existing methods, no matter based on reinforcement learning or evolutionary algorithms (EA), conduct architecture search in a discrete space, which is highly inefficient. In this paper, we propose a simple and efficient method to automatic neural architecture design based on continuous optimization. We call this new approach neural architecture optimization (NAO). There are three key components in our proposed approach: (1) An encoder embeds/maps neural network architectures into a continuous space. (2) A predictor takes the continuous representation of a network as input and predicts its accuracy. (3) A decoder maps a continuous representation of a network back to its architecture. The performance predictor and the encoder enable us to perform gradient based optimization in the continuous space to find the embedding of a new architecture with potentially better accuracy. Such a better embedding is then decoded to a network by the decoder. Experiments show that the architecture discovered by our method is very competitive for image classification task on CIFAR-10 and language modeling task on PTB, outperforming or on par with the best results of previous architecture search methods with a significantly reduction of computational resources. Specifically we obtain $2.07\%$ test set error rate for CIFAR-10 image classification task and $55.9$ test set perplexity of PTB language modeling task. The best discovered architectures on both tasks are successfully transferred to other tasks such as CIFAR-100 and WikiText-2.
翻译:现有方法,无论以强化学习或进化算法(EA)为基础,都是基于强化学习或进化算法(EA),都是在离散空间进行建筑搜索,这效率极低。在本文中,我们提出了一个基于连续优化的自动神经结构设计设计简单而有效的方法。我们称之为新方法神经结构优化(NAO),我们拟议方法中有三个关键组成部分:(1) 将神经网络结构嵌入/成一个连续空间。(2) 预测器将网络的连续表述作为输入和预测其准确性。(3) 解码器将网络的连续表述图解析回到其结构中,这是非常低效率的。 性能预测器和编码器使我们能够在连续空间进行基于优化的神经结构设计设计。我们称之为新方法神经结构优化。这样更好的嵌入随后由解码器解码到网络中。 实验显示,我们所发现的架构模型对于CFAR-10的图像分类任务和PTBT的语言建模任务具有很强的竞争力,比PTBT的运行或比值高出100美元。 性预测和编码使前FAR- 的FAR- 测试任务中的最佳结果的系统任务得到了最佳的测试。
相关内容

Source: Apple - iOS 8


